Top 85 Big Data Interview Questions and Answers for 2026

The global big data and business analytics market was valued at 169 billion U.S. dollars in 2018 and is expected to grow to 274 billion U.S. dollars in 2026, According Statista.
Big Data is a term that is used to describe the large and ever-growing volumes of data that is being created. Now Companies are using Big Data to make better decisions and to improve their operations, system efficiency. There are several ways to collect and use Big Data. Some of the most common methods include data mining, data analytics, and data visualization.
All organizations are using Big Data in every industry and it has been contributing to the expansion of automation and Artificial Intelligence (AI) segments. If we are looking for jobs in Big Data, you need to have a very good skill set and knowledge on technologies and tools of Big data. In Big data field, there are various work profiles like Data Scientist, Data Engineer, Big Data Engineer, Data Analyst, Machine learning scientist, Business analytics specialist, Data visualization developer, Business Intelligence developer, BI Solution architect, BI Specialist, Analytics manager, Machine learning engineer, Statistician and many others.
Here are the most commonly asked Big Data interview questions and their answers that will help you face your next Big Data interview. These questions are for big data interview questions for freshers and big data interview questions for experienced also.

1. What is BIG DATA?
Ans: Big Data is nothing but an assortment of such a huge and complex data that it becomes very tedious to capture, store, process, retrieve and analyze it with the help of on-hand database management tools or traditional data processing techniques.
2. Can you give some examples of Big Data?
Ans: There are many real life examples of Big Data! Facebook is generating 500+ terabytes of data per day, NYSE (New York Stock Exchange) generates about 1 terabyte of new trade data per day, a jet airline collects 10 terabytes of censor data for every 30 minutes of flying time. All these are day to day examples of Big Data!
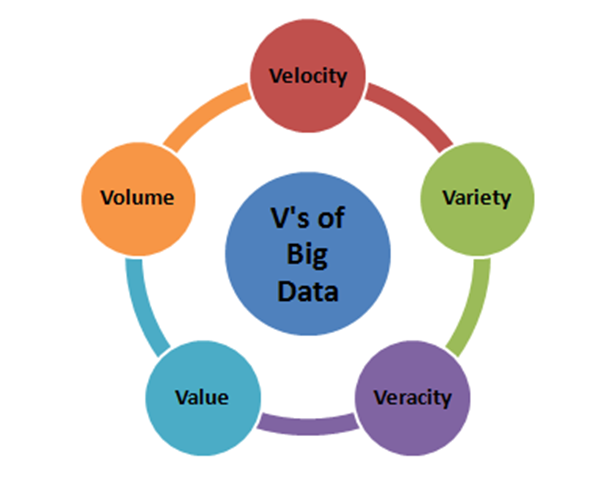
3. What are the five V’s of Big Data?
Answer: The five V’s of Big data is as follows:
Volume – Volume represents the volume i.e. amount of data that is growing at a high rate i.e. data volume in Petabytes
Velocity – Velocity is the rate at which data grows. Social media contributes a major role in the velocity of growing data.
Variety – Variety refers to the different data types i.e. various data formats like text, audios, videos, etc.
Veracity – Veracity refers to the uncertainty of available data. Veracity arises due to the high volume of data that brings incompleteness and inconsistency.
Value –Value refers to turning data into value. By turning accessed big data into values, businesses may generate revenue.
4. According to IBM, what are the three characteristics of Big Data?
Ans: According to IBM, the three characteristics of Big Data are: Volume: Facebook generating 500+ terabytes of data per day. Velocity: Analyzing 2 million records each day to identify the reason for losses. Variety: images, audio, video, sensor data, log files, etc.
5. What are some of the challenges associated with big data?
Ans: The challenges associated with big data include the following:
• Managing large volumes of data
• Managing data that is unstructured or semi-structured
• Extracting value from data
• Integrating data from multiple sources
6. Name some of the important tools useful for Big Data analytics.
Ans. It is one of the most commonly asked big data interview questions.
The important Big Data analytics tools are –
· NodeXL
· KNIME
· Tableau
· Solver
· OpenRefine
· Rattle GUI
· Qlikview
7. Why is Hadoop used in Big Data analytics?
Ans. Hadoop is an open-source framework in Java, and it processes even big volumes of data on a cluster of commodity hardware. It also allows running many exploratory data analysis tasks on full datasets, without sampling. Features that make Hadoop an essential requirement for Big Data are –
· Data collection
· Storage
· Processing
· Runs independently
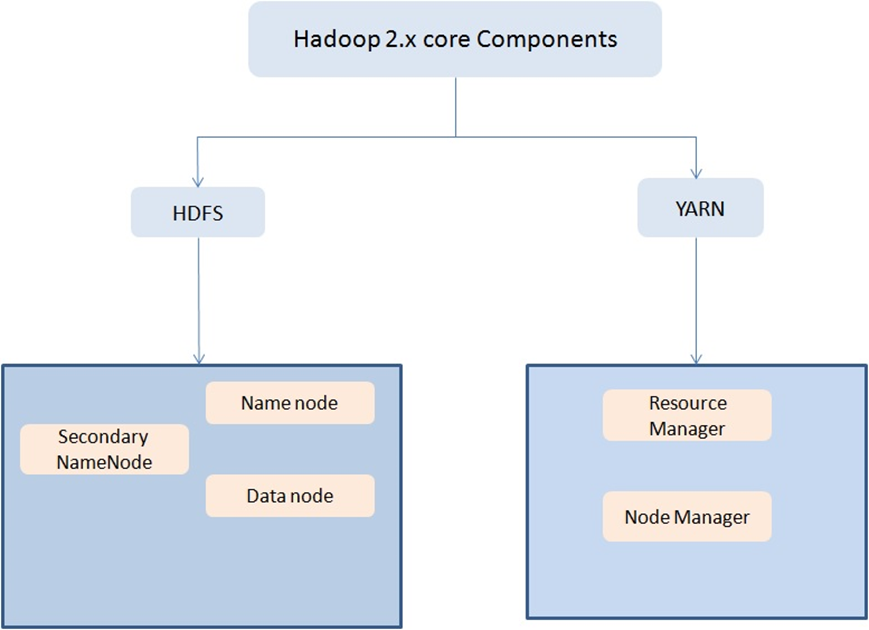
8. What are HDFS and YARN? What are their respective components?
Ans. HDFS or Hadoop Distributed File System runs on commodity hardware and is highly fault-tolerant. HDFS provides file permissions and authentication and is suitable for distributed storage and processing. It is composed of three elements, including NameNode, DataNode, and Secondary NameNode.
Read: Hadoop-HDFS Interview Questions
YARN is an integral part of Hadoop 2.0 and is an abbreviation for Yet Another Resource Negotiator. It is a resource management layer of Hadoop and allows different data processing engines like graph processing, interactive processing, stream processing, and batch processing to run and process data stored in HDFS. ResourceManager and NodeManager are the two main components of YARN.
9. How Big is Big Data?
Ans: With time, data volume is growing exponentially. Earlier we used to talk about Megabytes or Gigabytes. But time has arrived when we talk about data volume in terms of terabytes, petabytes and also zettabytes! Global data volume was around 1.8ZB in 2011 and is expected to be 7.9ZB in 2015. It is also known that the global information doubles in every two years!
Also Read:
Top 50 Big Data Analytics Tools and Software You should know in 2025
The Importance of Big Data Analytics in Business
How to Use Big Data Analytics to Steer Your Business in the Right Direction
The Interesting Evolution Of Big Data Analytics
Big Data Analytics: A Weapon Against Rising Cyber Security Attacks
Top 5 Interesting Big Data Applications in Education
Data and Analytics Help Day Trading Investors Make Good Investment Decisions
Which Are The Real Benefits of Big Data?
10. How analysis of Big Data is useful for organizations?
Ans: Effective analysis of Big Data provides a lot of business advantage as organizations will learn which areas to focus on and which areas are less important. Big data analysis provides some early key indicators that can prevent the company from a huge loss or help in grasping a great opportunity with open hands! A precise analysis of Big Data helps in decision making! For instance, nowadays people rely so much on Facebook and Twitter before buying any product or service. All thanks to the Big Data explosion.
11. Explain the steps to be followed to deploy a Big Data solution.
Answer: Followings are the three steps that are followed to deploy a Big Data Solution –
i. Data Ingestion
The first step for deploying a big data solution is the data ingestion i.e. extraction of data from various sources. The data source may be a CRM like Salesforce, Enterprise Resource Planning System like SAP, RDBMS like MySQL or any other log files, documents, social media feeds etc. The data can be ingested either through batch jobs or real-time streaming. The extracted data is then stored in HDFS.
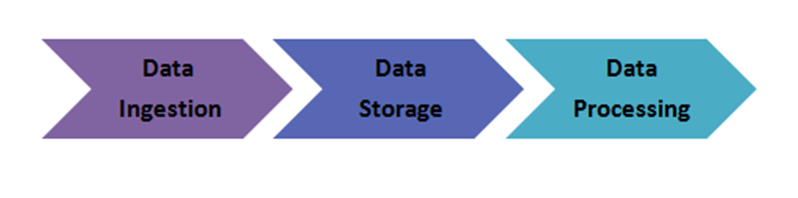
ii. Data Storage
After data ingestion, the next step is to store the extracted data. The data either be stored in HDFS or NoSQL database (i.e. HBase). The HDFS storage works well for sequential access whereas HBase for random read/write access.
iii. Data Processing
The final step in deploying a big data solution is the data processing. The data is processed through one of the processing frameworks like Spark, MapReduce, Pig, etc.
12. Who are Data Scientists?
Ans: Data scientists are soon replacing business analysts or data analysts. Data scientists are experts who find solutions to analyze data. Just as web analysis, we have data scientists who have good business insight as to how to handle a business challenge. Sharp data scientists are not only involved in dealing business problems, but also choosing the relevant issues that can bring value-addition to the organization.
13. What is Hadoop?
Ans. Hadoop is a framework that allows for distributed processing of large data sets across clusters of commodity computers using a simple programming model.
Read also:
Hadoop Cluster Interview Questions
Hadoop Admin Interview Questions
14. Name some key components of a Hadoop application.
Ans. The key components of a Hadoop application are –
· HDFS
· YARN
· Hadoop Common
15. Why the name Hadoop?
Ans. Hadoop doesn’t have any expanding version like oops. The charming yellow elephant you see is basically named after Dougs son’s toy elephant!
16. Why do we need Hadoop?
Ans. Everyday a large amount of unstructured data is getting dumped into our machines. The major challenge is not to store large data sets in our systems but to retrieve and analyze the big data in the organizations, that too data present in different machines at different locations. In this situation a necessity for Hadoop arises. Hadoop has the ability to analyze the data present in different machines at different locations very quickly and in a very cost effective way. It uses the concept of MapReduce which enables it to divide the query into small parts and process them in parallel. This is also known as parallel computing.
Read: MapReduce Interview Questions
17. What is FSCK?
Ans. FSCK or File System Check is a command used by HDFS. It checks if any file is corrupt, has its replica, or if there are some missing blocks for a file. FSCK generates a summary report, which lists the overall health of the file system.
18. What are the different file formats that can be used in Hadoop?
Ans. File formats used with Hadoop, include –
· CSV
· JSON
· Columnar
· Sequence files
· AVRO
· Parquet file
19. Name the most popular data management tools used with Edge Nodes in Hadoop.
Ans. The most commonly used data management tools that work with Edge Nodes in Hadoop are –
· Oozie
· Ambari
· Pig
· Flume
20. What are some of the characteristics of Hadoop framework?
Ans. Hadoop framework is written in Java. It is designed to solve problems that involve analyzing large data (e.g. petabytes). The programming model is based on Google’s MapReduce. The infrastructure is based on Google’s Big Data and Distributed File System. Hadoop handles large files/data throughput and supports data intensive distributed applications. Hadoop is scalable as more nodes can be easily added to it.
Also read:
Top 12 Hadoop Technology Companies
The Biggest Challenge of Hadoop Analytics: It’s all about Query Performance
Relation Between Big Data Hadoop and Cloud Computing
What Is Hadoop, And How Does It Relate To Cloud?
A Guide to Become a Successful Hadoop Developer in 2025
How To Kick Start Your Career With Hadoop And Big Data Training?
13 Reasons Why System/Data Administrators should do Hadoop Training
Top 10 Tips for Hadoop Administration for Starters
21. Give a brief overview of Hadoop history.
Ans. In 2002, Doug Cutting created an open source, web crawler project. In 2004, Google published MapReduce, GFS papers. In 2006, Doug Cutting developed the open source, Mapreduce and HDFS project. In 2008, Yahoo ran 4,000 node Hadoop cluster and Hadoop won terabyte sort benchmark. In 2009, Facebook launched SQL support for Hadoop.
22. Give examples of some companies that are using Hadoop structure?
Ans. A lot of companies are using the Hadoop structure such as Cloudera, EMC, MapR, Hortonworks, Amazon, Facebook, eBay, Twitter, Google and so on.
23. What is the basic difference between traditional RDBMS and Hadoop?
Ans. Traditional RDBMS is used for transactional systems to report and archive the data, whereas Hadoop is an approach to store huge amount of data in the distributed file system and process it. RDBMS will be useful when you want to seek one record from Big data, whereas, Hadoop will be useful when you want Big data in one shot and perform analysis on that later.

24. What is structured and unstructured data?
Ans. Structured data is the data that is easily identifiable as it is organized in a structure. The most common form of structured data is a database where specific information is stored in tables, that is, rows and columns. Unstructured data refers to any data that cannot be identified easily. It could be in the form of images, videos, documents, email, logs and random text. It is not in the form of rows and columns.
25. What are the core components of Hadoop?
Ans. Core components of Hadoop are HDFS and Map Reduce. HDFS is basically used to store large data sets and Map Reduce is used to process such large data sets.
26. Name various Hadoop and YARN daemons.
Ans.
Hadoop daemons
· NameNode
· Datanode
· Secondary NameNode
YARN daemons
· ResourceManager
· NodeManager
· JobHistoryServer
27. What is HDFS?
Ans. HDFS is a file system designed for storing very large files with streaming data access patterns, running clusters on commodity hardware.
28. What are the key features of HDFS?
Ans. HDFS is highly fault-tolerant, with high throughput, suitable for applications with large data sets, streaming access to file system data and can be built out of commodity hardware.
29. What is the bias-variance tradeoff?
Ans. It is the bias that represents the precision of a model. A model with a high bias tends to be oversimplified and results in insufficient fit. The variance represents the sensitivity of the model to data and noise. A model with high variance results in overfitting.
Therefore, the trade-off between bias and variance is a property of machine learning models in which lower variance leads to higher bias and vice versa. In general, an optimal balance of the two can be found in which error is minimized.
30. What is Fault Tolerance?
Ans: Suppose you have a file stored in a system, and due to some technical problem that file gets destroyed. Then there is no chance of getting the data back present in that file. To avoid such situations, Hadoop has introduced the feature of fault tolerance in HDFS. In Hadoop, when we store a file, it automatically gets replicated at two other locations also. So even if one or two of the systems collapse, the file is still available on the third system.
31.What is the difference between a Hadoop database and Relational Database?
Ans: Hadoop is not a database, it is an architecture with a filesystem called HDFS. The data is stored in HDFS which does not have any predefined containers. Relational database stores data in predefined containers.
32. What is MAP REDUCE?
Ans: Map Reduce is a set of programs used to access and manipulate large data sets over a Hadoop cluster.
33. What is the InputSplit in map reduce software?
Ans: An inputsplit is the slice of data to be processed by a single Mapper. It generally is of the block size which is stored on the datanode.
34. What is the Central Limit Theorem (CLT)? How would you determine if the distribution is normal?
Ans. The central limit theorem states that the distribution of the sample means approaches a normal distribution as the sample size increases regardless of the shape of the population distribution.
35. What is the meaning of the Replication factor?
Ans. Replication factor defines the number of times a given data block is stored in the cluster. The default replication factor is 3. This also means that you need to have 3times the amount of storage needed to store the data. Each file is split into data blocks and spread across the cluster.
36. What is the default replication factor in HDFS?
Ans. The default hadoop comes with 3 replication factor. You can set the replication level individually for each file in HDFS. In addition to fault tolerance having replicas allow jobs that consume the same data to be run in parallel. Also if there are replicas of the data hadoop can attempt to run multiple copies of the same task and take which ever finishes first. This is useful if for some reason a box is being slow. Most Hadoop administrators set the default replication factor for their files to be three. The main assumption here is that if you keep three copies of the data, your data is safe. this to be true in the big clusters that we manage and operate. In addition to fault tolerance having replicas allow jobs that consume the same data to be run in parallel. Also if there are replicas of the data Hadoop can attempt to run multiple copies of the same task and take whichever finishes first. This is useful if for some reason a box is being slow.
37. What are the main differences between NAS (Network-attached storage) and HDFS?
Answer: The main differences between NAS (Network-attached storage) and HDFS –
HDFS runs on a cluster of machines while NAS runs on an individual machine. Hence, data redundancy is a common issue in HDFS. On the contrary, the replication protocol is different in case of NAS. Thus the chances of data redundancy are much less.
Data is stored as data blocks in local drives in case of HDFS. In case of NAS, it is stored in dedicated hardware.
38. What is ‘cross-validation’?
Ans. It is among the most popular big data interview questions.
Cross-validation can be difficult to explain, especially in an easy and understandable way.
Cross-validation is used to analyze whether an object can function as expected once it is used on live servers. In other words, it looks at how certain specific statistical analysis results are valued when an independent data set is put in.
39. What is ‘cluster sampling’?
Ans. Cluster sampling is a sampling method that helps the researcher to divide the population into separate groups, called clusters. Then a simple cluster sample is selected from the population and the data is analyzed from the sample clusters.
40. What is the Command to format the NameNode?
Answer: $ hdfs namenode -format
41. what is the typical block size of an HDFS block?
Ans: Default blocksize is 64mb. But 128mb is typical.
42. What is the difference between “HDFS Block” and “Input Split”?
The HDFS divides the input data physically into blocks for processing which is known as HDFS Block.
Input Split is a logical division of data by mapper for mapping operation.
43. How does master slave architecture in the Hadoop?
Ans: Totally 5 daemons run in Hadoop Master-slave architecture . On Master Node : Name Node and Job Tracker and Secondary name node On Slave : Data Node and Task Tracker But its recommended to run Secondary name node in a separate machine which have Master node capacity.
43. What are compute and Storage nodes?
Ans: I do define Hadoop into 2 ways : Distributed Processing : MapReduce Distributed Storage : HDFS Name Node holds Meta info and Data holds exact data and its MR program.
44. Which hardware configuration is most beneficial for Hadoop jobs?
Dual processors or core machines with a configuration of 4 / 8 GB RAM and ECC memory is ideal for running Hadoop operations. However, the hardware configuration varies based on the project-specific workflow and process flow and need customization accordingly.
45. What do you understand by Rack Awareness in Hadoop?
It is an algorithm applied to the NameNode to decide how blocks and its replicas are placed. Depending on rack definitions network traffic is minimized between DataNodes within the same rack. For example, if we consider replication factor as 3, two copies will be placed on one rack whereas the third copy in a separate rack.
46. Explain how input and output data format of the Hadoop framework?
Ans: Fileinputformat, textinputformat, keyvaluetextinputformat, sequencefileinputformat, sequencefileasinputtextformat, wholefileformat are file formats in hadoop framework.
47. What is the Hierarchical Clustering Algorithm?
Ans. The hierarchical grouping algorithm is the one that combines and divides the groups that already exist, in this way they create a hierarchical structure that presents the order in which the groups are split or merged.
48. What is K-mean clustering?
Ans. K mean clustering is a method of vector quantization. With this method, objects are classified as belonging to one of the K groups, which are selected as a priori.
49. What is n-gram?
Ans. N-gram is a continuous sequence of n elements of a given voice or text. The N-gram is a type of probabilistic language model used in the prediction of the next item in the sequence in the form of (n-1).
50. How can we control particular key should go in a specific reducer?
Ans. By using a custom partitioner.
Also read:
Data Science – The MUST KNOW to become a successful Data Scientist!
How can software engineers and data scientists work together?
Top Data Scientist Skills You May Need In 2025
Essential Tips for Beginner Data Scientists
What Data Scientists Need to Know About SQL
10 Essential Skills You Need To Be A Data Scientist!
Why Is Learning SAS An Important Step In Becoming A Data Scientist?
51. What is the Reducer used for?
Ans. Reducer is used to combine the multiple outputs of mapper to one.
52. What are the primary phases of the Reducer?
Ans: Reducer has 3 primary phases: shuffle, sort and reduce.
53. What happens if number of reducers are 0?
Ans: It is legal to set the number of reduce-tasks to zero if no reduction is desired. In this case the outputs of the map-tasks go directly to the FileSystem, into the output path set by setOutputPath(Path). The framework does not sort the map-outputs before writing them out to the FileSystem.
54.How many instances of JobTracker can run on a HadoopCluser?
Ans: One. There can only be one JobTracker in the cluster. This can be run on the same machine running the NameNode.
55. Why is Hadoop used for Big Data Analytics?
Answer: Since data analysis has become one of the key parameters of business, hence, enterprises are dealing with massive amounts of structured, unstructured and semi-structured data. Analyzing unstructured data is quite difficult where Hadoop takes major part with its capabilities of
· Storage
· Processing
· Data collection
Moreover, Hadoop is open source and runs on commodity hardware. Hence it is a cost-benefit solution for businesses.
56. Explain JobTracker in Hadoop
JobTracker is a JVM process in Hadoop to submit and track MapReduce jobs.
JobTracker performs the following activities in Hadoop in a sequence –
· JobTracker receives jobs that a client application submits to the job tracker
· JobTracker notifies NameNode to determine data node
· JobTracker allocates TaskTracker nodes based on available slots.
· it submits the work on allocated TaskTracker Nodes,
· JobTracker monitors the TaskTracker nodes.
· When a task fails, JobTracker is notified and decides how to reallocate the task.
57. How NameNode Handles data node failures?
Ans: Through checksums. every data has a record followed by a checksum. if checksum doesnot match with the original then it reports an data corrupted error.
58. What is Distributed Cache in a MapReduce Framework
Distributed Cache is a feature of Hadoop MapReduce framework to cache files for applications. Hadoop framework makes cached files available for every map/reduce tasks running on the data nodes. Hence, the data files can access the cache file as a local file in the designated job.
59. Can I set the number of reducers to zero?
Ans. can be given as zero. So, the mapper output is finalized output and stored in HDFS.
60. What is a SequenceFile in Hadoop?
Ans: A. Sequence File contains a binary encoding of an arbitrary number of homogeneous writable objects.
B. ASequenceFilecontains a binary encoding of an arbitrary number of heterogeneous writable objects. C. ASequenceFilecontains a binary encoding of an arbitrary number of WritableComparable objects, in sorted order. D. ASequenceFilecontains a binary encoding of an arbitrary number key-value pairs. Each key must be the same type. Each value must be sametype.
Also read:
Types and Examples of NoSQL Databases
40 Best Free and Open Source NoSQL Databases
Why NoSQL is the future of IoT
Adapting NoSQL Syntax to SQL Databases
MongoDB, Cassandra, and HBase-the three NoSQL databases to watch
5 Questions Enterprises Should Ask When Selecting a NoSQL Database
What are the Best Practices for SQL Server That Saves It from Damages?
What Data Scientists Need to Know About SQL
The Limitation of MySQL Database in a Typical Big Data Environment
Business Intelligence Benchmark for SQL-on-Hadoop Engines
61. How many states does the Writable interface define ___ in Hadoop?
Ans. Two
62. What are sequence files and why are they important in Hadoop?
Ans: Sequence files are binary format files that are compressed and are splittable. They are often used in high-performance map-reduce jobs
63. What are map files and why are they important in Hadoop?
Ans: Map files are sorted sequence files that also have an index. The index allows fast data look up.
64. How can you use binary data in MapReduce in Hadoop?
Ans. Binary data can be used directly by a map-reduce job. Often binary data is added to a sequence file.
65. What is map – side join in Hadoop?
Ans. Map-side join is done in the map phase and done in memory
66. What is reduce – side join in Hadoop?
Ans: Reduce-side join is a technique for merging data from different sources based on a specific key. There are no memory restrictions
67. How can you disable the reduce step in Hadoop?
Ans : A developer can always set the number of the reducers to zero. That will completely disable the reduce step.
68. Why would a developer create a map-reduce without the reduce step Hadoop?
Ans: There is a CPU intensive step that occurs between the map and reduce steps. Disabling the reduce step speeds up data processing.
69. What is the default input format in Hadoop?
Ans: The default input format is TextInputFormat with byte offset as a key and entire line as a value.
70. How can you overwrite the default input format in Hadoop?
Ans: In order to overwrite default input format, a developer has to set new input format on job config before submitting the job to a cluster.
71. Is there a map input format in Hadoop?
Ans: No, but sequence file input format can read map files.
72. What are the common input formats in Hadoop?
Answer: Below are the common input formats in Hadoop –
Text Input Format – The default input format defined in Hadoop is the Text Input Format.
Sequence File Input Format – To read files in a sequence, Sequence File Input Format is used.
Key Value Input Format – The input format used for plain text files (files broken into lines) is the Key Value Input Format.
73. What is a mapper?
A mapper is a MapReduce function that breaks a big data set into smaller pieces.
74. What is Hive?
Hive is a data warehousing system for Hadoop that makes it easy to query and analyze big data sets.
Read: Hive Interview Questions
75. What is Apache Flume?
Apache Flume is a tool for collecting, aggregating, and transferring large amounts of data.
76. What is Oozie?
Oozie is a workflow scheduling system for Hadoop. Oozie can be used to schedule MapReduce, Pig, and Hive jobs.
77. What is Zookeeper?
Zookeeper is a distributed coordination service for Hadoop. Zookeeper is used to manage the configuration of Hadoop clusters and to coordinate the activities of the services that run on Hadoop.
78. What is Apache Ambari?
Ambari is a web-based interface for managing Hadoop clusters.
79. What is HCatalog?
HCatalog is a metadata management system for Hadoop. HCatalog makes it easy to access data stored in Hadoop.
80. What is Avro?
Avro is a data serialization system for Hadoop. Avro allows data to be transferred between Hadoop and other systems.
81. What is Parquet?
Parquet is a columnar storage format for Hadoop. Parquet is designed to improve the performance of MapReduce jobs.
82. What is Cassandra?
Cassandra is a NoSQL database that is designed to be scalable and highly available.
83. What is HBase?
HBase is a columnar database that is designed to be scalable and highly available.
84. What is Apache Pig?
Apache Pig is a data processing language for Hadoop that makes it easy to write MapReduce programs.
Read: Apace Pig Interview questions
85. What is Sqoop?
Apache Sqoop is a tool for transferring data between Hadoop and relational databases.
Other Interview Question Articles You may like to explore:
Hadoop-HDFS Interview Questions
Hadoop Cluster Interview Questions
Hadoop Admin Interview Questions
MongoDB Interview Questions
MongoDB-NoSQl Interview Questions
Splunk Interview Questions
Apache Pig Interview Questions
Hive Interview Questions
MapReduce Interview Questions
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...