40 Best Free and Open Source NoSQL Databases
 NoSQL databases are becoming popular day by day. I have come up with the list of best, free and open source NoSQL databases. MongoDB tops the list of Open Source NoSQL databases. This list of free and open source databases comprises of MongoDB, Cassandra, CouchDB, Hypertable, Redis, Riak, Neo4j, HBASE, Couchbase, MemcacheDB, RevenDB and Voldemort. These free nosql database list and open source NoSQL databases are really highly scale-able, flexible and good for big data storage and processing. These open source NoSQL databases are far ahead in terms of performance as compared to traditional relational databases.
NoSQL databases are becoming popular day by day. I have come up with the list of best, free and open source NoSQL databases. MongoDB tops the list of Open Source NoSQL databases. This list of free and open source databases comprises of MongoDB, Cassandra, CouchDB, Hypertable, Redis, Riak, Neo4j, HBASE, Couchbase, MemcacheDB, RevenDB and Voldemort. These free nosql database list and open source NoSQL databases are really highly scale-able, flexible and good for big data storage and processing. These open source NoSQL databases are far ahead in terms of performance as compared to traditional relational databases.
According to the report published by Zion Market Research, the global NoSQL Database Market size was valued at USD 9.38 Billion in 2023 and is predicted to reach USD 86.48 Billion by the end of 2032. The market is expected to grow with a CAGR of 28% during the forecast period.
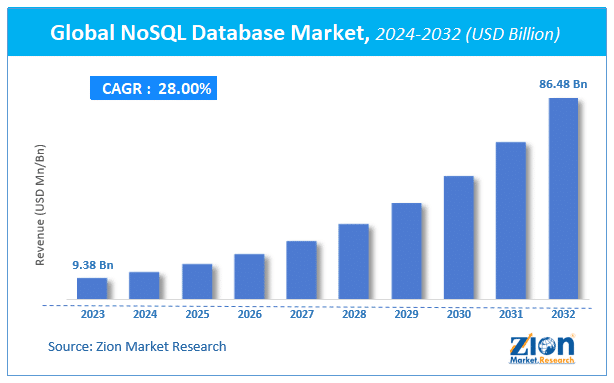
The growth of the market is attributed to the increasing implementation of Big Data among various industry verticals. Moreover, the growing awareness of NOSQL benefits for various web applications is stimulating market growth.
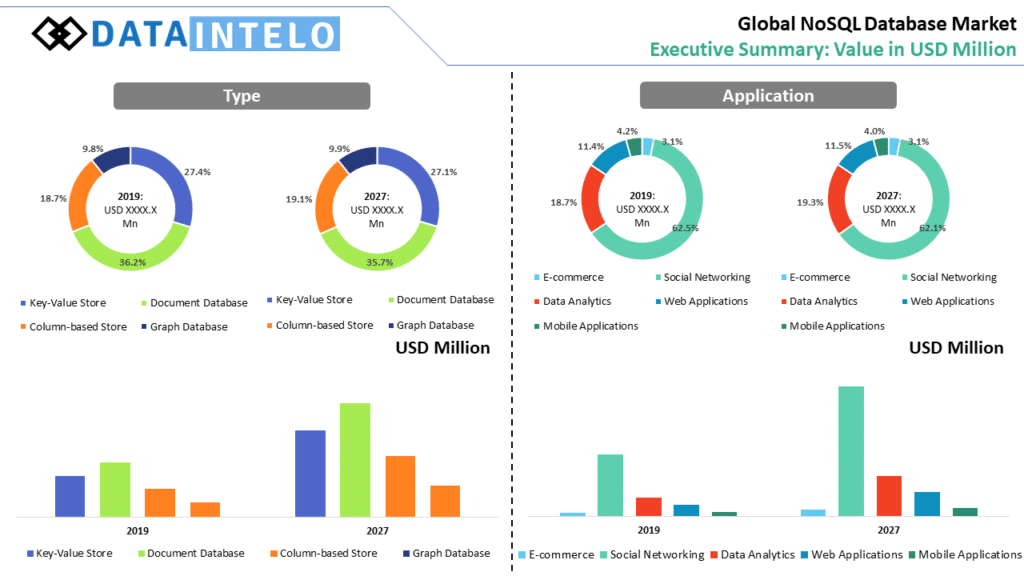
NoSQL also called “Not Only SQL” facilitates the storage and retrieval of data in a non-relational database format. Unlike, a relational database (RDBMS), NoSQL allows the related to be structure in a unified structure. The widespread adoption of these databases proliferated after the 2000s owing to the decreased cost of the storage and the increasing data processing requirements. Furthermore, NoSQL has a dynamic schema that makes them feasible for content management systems, real-time analytics, and a rise in unstructured data applications. However, these may not be always the best choice for you. Most of common applications can still be developed using traditional relational databases. NoSQL databases are still not the best option for a mission critical transaction needs.
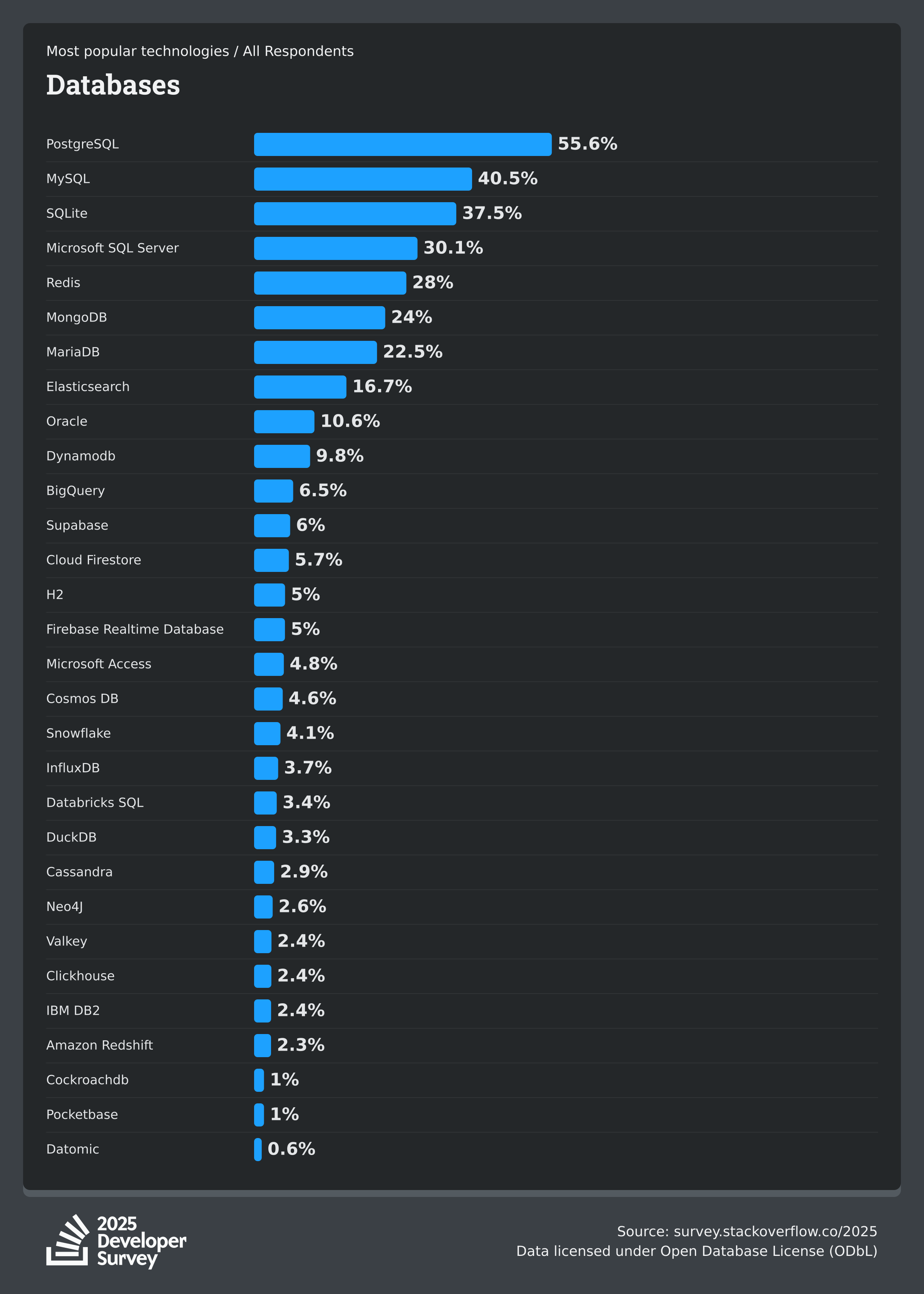
As per Stackoverflow Developer Survey 2025, PostgreSQL took over the first place spot from MySQL. Professional Developers are more likely than those learning to code to use PostgreSQL (50%) and those learning are more likely to use MySQL (54%).
The significant growth in usage for Redis (+8%) highlights its growing importance. As applications become more complex, the need for high-speed, in-memory caching and data structures has made Redis an essential part of the modern tech stack.
MongoDB is used by a similar percentage of both Professional Developers and those learning to code and it’s the second most popular database for those learning to code (behind MySQL).
According to Statista, As of November 2023, the most popular open source database management system (DBMS) in the world was MySQL, with a ranking score of 1115. Oracle was the most popular commercial DBMS at that time, with a ranking score of 1277.
Market Growth & Size
- Valuation: Estimates place the market around $9-12 billion in 2024, with projections to exceed $80 billion by the early 2030s.
- CAGR: Expect a Compound Annual Growth Rate (CAGR) of roughly 28-30% through the decade.
Key Drivers & Trends
- Big Data & IoT: Handling massive volumes of unstructured/semi-structured data from the web, mobile apps, and IoT.
- Scalability & Flexibility: NoSQL’s ability to scale horizontally and offer flexible schemas beats traditional relational databases (RDBMS) for modern needs.
- AI & Machine Learning: Growth in vector databases and embedding support for AI/ML pipelines.
- Cloud-Native & Hybrid: Increased adoption in cloud environments and hybrid models for cost/flexibility.
- Microservices: Supporting polyglot persistence in microservices architectures.
Market Leaders & Segments
- Top Players: MongoDB, Amazon DynamoDB, and others lead.
- Dominant Type: Key-Value stores often lead, but graph and other types are rising.
We have listed down a small description of all these best free NoSQL datbase and open source NoSQL databases. Lets have a look.
1. MongoDB
MongoDB is a document-oriented database that uses a JSON-style data format. It’s ideal for website data storage, content management and caching applications, and can be configured for replication and high availability.
This highly scale-able and agile NoSQL database is a amazing performing system. This NoSQL open source database written in C++ comes with a storage that is document oriented. Also, you will be provided with benefits like full index support, high availability across WANs and LANs along with easy replication, horizontal scaling, rich queries that are document based, flexibility in data processing and aggregation along with proper training, support and consultation.
MongoDB can be installed locally, which will allow you to host your own MongoDB server on your hardware. This requires you to manage your server, upgrades, and any other maintenance.
2. Cassandra
An Apache Software Foundation project, Cassandra is a distributed database that allows for decentralized data storage that is fault tolerant and has no single point of failure. In other words, “Cassandra is suitable for applications that can’t afford to lose data.”
3. CouchDB
A product of the Apache Software Foundation, CouchDB is another document-oriented database that stores data in free JSON database format. It’s ACID compliant, and like MongoDB, can be used to store data and content for websites, and to provide caching. You can use JavaScript to run MapReduce Queries on CouchDB. It also provides a very convenient web based administration console. This database could be really handy for web applications.

![]()
4. Hypertable
Modeled after Google’s BigTable database system, Hypertable’s creators aim for it to be the “open source standard for highly available, petabyte scale, database systems.” In other words, Hypertable is designed for storing massive amounts of data reliably across many cheap servers.
5. Redis
This is an open source nosql, key value store of an advanced level. Owing to the presence of hashes, sets, strings, sorted sets and lists in a key; Redis is also called as a data structure server. This system will help you in running atomic operations like incrementing value present in a hash, set intersection computation, string appending, difference and union. Redis makes use of in-memory dataset to achieve high performance. Also, this system is compatible with most of the programming languages.
6. Riak
Riak is one of the most powerful, distributed databases ever to be introduced. It provides for easy and predictable scaling and equips users with the ability for quick testing, prototyping and application deployment so as to simplify development.
7. Neo4j
This is a NoSQL graph database which exhibits a high level of performance. It comes well equipped with all the features of a robust and mature system. It provides the programmers with a flexible and object oriented network structure and allows them to enjoy all the benefits of a database that is fully transactional. Compared to RDBMS, Neo4j will also provide you with performance improvements on some of the applications.
Also read:
Top 12 Hadoop Technology Companies
The Biggest Challenge of Hadoop Analytics: It’s all about Query Performance
Relation Between Big Data Hadoop and Cloud Computing
What Is Hadoop, And How Does It Relate To Cloud?
A Guide to Become a Successful Hadoop Developer in 2022
How To Kick Start Your Career With Hadoop And Big Data Training?
13 Reasons Why System/Data Administrators should do Hadoop Training
Top 10 Tips for Hadoop Administration for Starters
8. Hadoop HBASE
HBase can be easily considered as a scalable, distributed and a big data store. This database can be used when you are looking for real time and random access to your data. It comes with modular and linear scalability along with reads and writes that are strictly consistent. Other features include Java API that has an easy client access, table sharing that is configurable and automatic, Bloom filters and block caches and much more.
![]()
9. Couchbase
While Couchbase was a fork of CouchDB, it has become more of a full-fledged data product and less of a ball of framework than CouchDB. Its transition to a document database will give MongoDB a run for its money. It is multithreaded per node, which can be a major scalability benefit — especially when hosted on custom or bare-metal hardware. With some nice integration features, including with Hadoop, Couchbase is a great choice for an operational data store.
10. MemcacheDB
MemcacheDB is a distributed storage system of key value. It should not be confused with a cache solution; rather, it is a persistent storage engine which is meant for data storage and retrieval in a fast and reliable manner. Confirmation to memcache protocol is provided for. The storing backend that is used is the Berkeley DB which supports features like replication and transaction.
11. REVENDB
RAVENDB is a second generation open source DB. This DB is document oriented and schema free such as you simply have to dump in your objects into it. It provides extremely flexible and fast queries. This application makes scaling extremely easy by providing out-of-the-box support for replication, multi tenancy and sharding. There is full support for ACID transactions along with safety of your data. Easy extensibility via bundles is provided along with high performance.
12. Voldemort
This is an automatically replicating distributed storage system. It provides for automatic partitioning of data, transparent handling of server failure, pluggable serialization, independence of nodes and versioning of data items along with support for data distribution across various centers.
13. Perst
Perst is McObject’s open source, dual license, object-oriented embedded database system (ODBMS). It is available in one edition developed as an all-Java embedded database, and another implemented in C# (for Microsoft .NET Framework applications).
14. HyperGraphDB
HyperGraphDB is a general purpose, open-source data storage mechanism based on a powerful knowledge management formalism known as directed hypergraphs. While a persistent memory model designed mostly for knowledge management, AI and semantic web projects, it can also be used as an embedded object-oriented database for Java projects of all sizes. Or a graph database. Or a (non-SQL) relational database. Discover innovative database project ideas that can help you enhance your skills, from creating dynamic web applications to developing complex data management systems.
15. Terrastore
Terrastore is a modern document store which provides advanced scalability and elasticity features without sacrificing consistency. Terrastore is based on Terracotta, so it relies on an industry-proven, fast (and cool) clustering technology.
16. NeoDatis
NeoDatis ODB is a very simple Object Database that currently runs on the Java, .Net, Google Android, Groovy and Scala. To avoid Impedance mismatch overhead between Object and Relational worlds, give a try to Neodatis ODB. NeoDatis ODB is a new generation Object Database: a real native and transparent persistence layer for Java, .Net and Mono.
17. MyOODB
MyOODB is a Database and Application Framework. Bring the power of Object-Oriented-Design back to Application and Web Development!
18. OrientDB
OrientDB is the world’s fastest graph database. Period. An independent benchmark study by IBM and the Tokyo Institute of Technology showed that OrientDB is 10x faster than Neo4j on graph operations among all the workloads. Drive competitive advantage and accelerate innovation with new revenue streams.
19. Apache Drill
Apache Drill is a schema-free query engine for use with NoSQL or Hadoop data or file storage systems and databases.
20. Amazon Neptune
Amazon Neptune is a fully managed graph database built to support study and storage of relationship rich data (e.g. social network data, fraud detection).
21. ArangoDB
ArangoDB is a distributed free and open-source database with a flexible data model for documents, graphs, and key-values. Build high performance applications using a convenient SQL-like query language or JavaScript extensions.
22. eXist-db
eXist-db is an open source database management system entirely built on XML technology. It stores XML data according to the XML data model and features efficient, index-based XQuery processing.
23. RethinkDB
RethinkDB is built to store JSON documents, and scale to multiple machines with very little effort. It has a pleasant query language that supports really useful queries like table joins and group by, and is easy to setup and learn.
24. TIMi
With TIMi, companies can capitalize on their corporate data to develop new ideas and make critical business decisions faster and easier than ever before. The heart of TIMi’s Integrated Platform. TIMi’s ultimate real-time AUTO-ML engine. 3D VR segmentation and visualization. Unlimited self service business Intelligence. TIMi is several orders of magnitude faster than any other solution to do the 2 most important analytical tasks: the handling of datasets (data cleaning, feature engineering, creation of KPIs) and predictive modeling.
Also Read:
Top 50 Big Data Analytics Tools and Software You should know in 2022
The Importance of Big Data Analytics in Business
How to Use Big Data Analytics to Steer Your Business in the Right Direction
The Interesting Evolution Of Big Data Analytics
Big Data Analytics: A Weapon Against Rising Cyber Security Attacks
Top 5 Interesting Big Data Applications in Education
Data and Analytics Help Day Trading Investors Make Good Investment Decisions
Which Are The Real Benefits of Big Data?
25. Percona Server for MongoDB
Percona Server for MongoDB is a free and open-source drop-in replacement for MongoDB Community Edition. It combines all the features and benefits of MongoDB Community Edition with enterprise-class features from Percona. Built on the MongoDB Community Edition, Percona Server for MongoDB provides flexible data structure, native high availability, easy scalability, and developer-friendly syntax. It also includes an in-memory engine, hot backups, LDAP authentication, database auditing, and log redaction.
26. Google Cloud Firestore
Cloud Firestore is a fast, fully managed, serverless, cloud-native NoSQL document database that simplifies storing, syncing, and querying data for your mobile, web, and IoT apps at global scale. Its client libraries provide live synchronization and offline support, while its security features and integrations with Firebase and Google Cloud Platform (GCP) accelerate building truly serverless apps.
27. Google Cloud Datastore
Datastore is a highly scalable NoSQL database for your applications. Datastore automatically handles sharding and replication, providing you with a highly available and durable database that scales automatically to handle your applications’ load. Datastore provides a myriad of capabilities such as ACID transactions, SQL-like queries, indexes, and much more.
28. BangDB
BangDB natively integrates AI, streaming, graph, analytics within the DB itself to enable users to deal with complex data of different kinds, such as text, images, videos, objects etc. for real time data processing and analysis Ingest or stream any data, process it, train models, do prediction, find patterns, take action and automate all these to enable use cases such as IOT monitoring, fraud or disruption prevention, log analysis, lead generation, 1-on-1 personalisation and many more. Today’s use cases require different kinds of data to be ingested, processed, and queried at the same time for a given problem.
29. Amazon DynamoDB
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It’s a fully managed, multiregion, multimaster, durable database with built-in security, backup and restore, and in-memory caching for internet-scale applications. DynamoDB can handle more than 10 trillion requests per day and can support peaks of more than 20 million requests per second.
30. Restdb.io
restdb.io is a simple NoSQL database backend as a service (DBaaS). With very little effort and no coding, you can quickly set up an online database with a user friendly browser-based admin interface and a secure REST API. Add a few “low” code javascript hooks and background jobs and you can automate anything, making it a perfect data storage mechanism for various application workflows. restdb.io comes with a free plan for up to three users.
Also read:
Types and Examples of NoSQL Databases
Why NoSQL is the future of IoT
Adapting NoSQL Syntax to SQL Databases
MongoDB, Cassandra, and HBase-the three NoSQL databases to watch
5 Questions Enterprises Should Ask When Selecting a NoSQL Database
31. NCache
NCache is an open source distributed cache for .NET Framework & .NET Core (released under Apache License, Version 2.0), by Alachisoft. NCache provides an extremely fast and linearly scalable distributed cache that caches application data and reduces expensive database trips.Organizations use NCache to remove performance bottlenecks related to their data storage and databases and can scale their .NET and Java applications to extreme transaction processing (XTP).
32. SAP HANA
SAP HANA in-memory database is for transactional and analytical workloads with any data type — on a single data copy. It breaks down the transactional and analytical silos in organizations, for quick decision-making, on premise and in the cloud. Innovate without boundaries on a database management system, where you can develop intelligent and live solutions for quick decision-making on a single data copy. And with advanced analytics, you can support next-generation transactional processing. Build data solutions with cloud-native scalability, speed, and performance.
33. MarkLogic
The MarkLogic Data Hub Platform integrates and curates your enterprise data to provide immediate business value. Running on a NoSQL foundation for speed and scale, it’s multi-model, elastic, transactional, secure, and built for the cloud.
34. Aerospike
Aerospike is the global leader in next-generation, real-time NoSQL data solutions for any scale. Aerospike enterprises overcome seemingly impossible data bottlenecks to compete and win with a fraction of the infrastructure complexity and cost of legacy NoSQL databases. Aerospike’s patented Hybrid Memory Architecture™ delivers an unbreakable competitive advantage by unlocking the full potential of modern hardware, delivering previously unimaginable value from vast amounts of data at the edge, to the core and in the cloud.
35. AllegroGraph
AllegroGraph is a breakthrough solution that allows infinite data integration through a patented approach unifying all data and siloed knowledge into an Entity-Event Knowledge Graph solution that can support massive big data analytics. AllegroGraph utilizes unique federated sharding capabilities that drive 360-degree insights and enable complex reasoning across a distributed Knowledge Graph.
36. ScyllaDB
ScyllaDB is the world’s fastest NoSQL database. Accelerate application performance with the fastest NoSQL database, capable of millions of IOPS per node at less than 1 millisecond latency. Scylla is a drop-in Apache Cassandra or Amazon DynamoDB alternative that powers your applications with ultra-low latency and extreme throughput. We built upon the best high availability database features to create a dramatically higher-performing, more fault tolerant and resource effective NoSQL database to power demanding, modern applications. Written from the ground-up in C++ for Linux to create a fundamentally superior high availability database.
37. Azure Cosmos DB (Microsoft)
Azure Cosmos DB is a fully managed NoSQL database service for modern app development with guaranteed single-digit millisecond response times and 99.999-percent availability backed by SLAs, automatic and instant scalability, and open source APIs for MongoDB and Cassandra. Enjoy fast writes and reads anywhere in the world with turnkey multi-master global distribution.
38. Moon Modeler (Datensen)
Moon Modeler is a schema design and data modeling tool for various databases. Draw ER diagrams, reverse engineer existing database structures and generate SQL code. Supported platforms:
– MongoDB
– PostgreSQL
– MySQL
– MariaDB
– SQLite
– Mongoose
– GraphQL
39. Qubole
Qubole is a software organization based in the United States that offers a piece of software called Qubole. Qubole offers business hours and online support. Qubole features training via documentation and webinars. The Qubole software suite is SaaS software. Qubole is big data software, and includes features such as auto-sharding, automatic database replication, data model flexibility, deployment flexibility, dynamic schemas, integrated caching, Multi-Model, performance management, and security management.
40. Oracle Berkeley DB
Berkeley DB is a family of embedded key-value database libraries providing scalable high-performance data management services to applications.
]Originally published February 22, 2014 5:04 am, updated on Dec 24 2025 for relevance and comprehensiveness.]
Related Posts

7 Top Autonomous AI Pentesting Platforms in 2026
June 10, 2026Autonomous penetration testing is becoming one of the most important changes in ...

Why Embedded Analytics Is Replacing Standalone BI for Customer-Facing Use Cases
May 16, 2026The business intelligence market is undergoing an architectural split. For internal reporting ...

Best 7 Real-time Data Ingestion Tools for Snowflake
May 14, 2026Snowflake pipelines are no longer evaluated only by how well they support ...

Designing Predictive Pipelines: How Enterprises Turn Data into Foresight
December 26, 2025Predictive analytics is now a structured part of how many enterprises operate. ...
How AI-Driven Mobility Data Is Transforming Urban Transportation in 2026
November 17, 2025Rent a car dubai services are increasingly relying on advanced data analytics ...