Top Machine Learning Trends to watch in 2026

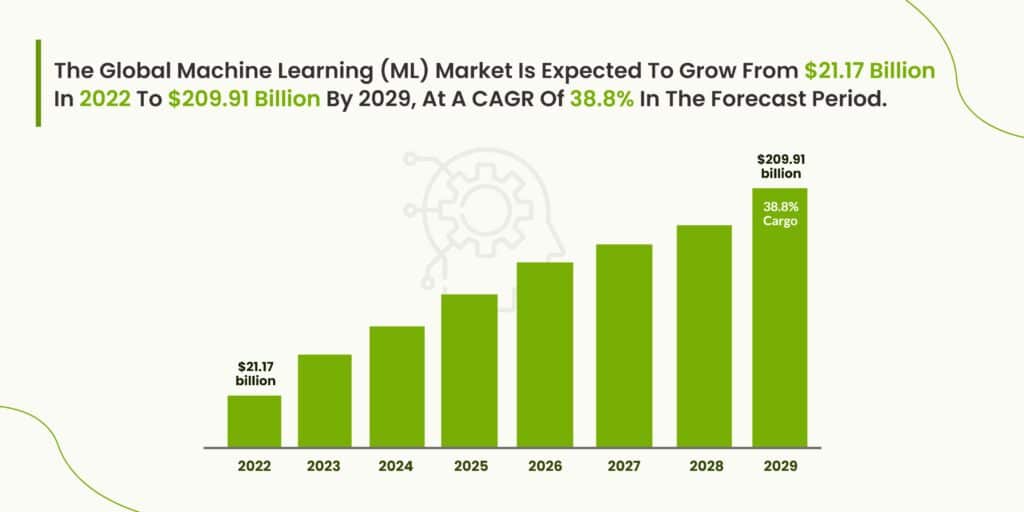
Although machine learning is one part of the greater AI market, it is the most commonly implemented form of AI and growing rapidly in business. The global machine learning (ML) market is expected to grow from $21.17 billion in 2022 to $209.91 billion by 2029, at a CAGR of 38.8% in forecast period.
The global Machine Learning (ML) market size was valued at USD 35.32 billion in 2024. The market is expected to grow from USD 47.99 billion in 2025 to USD 309.68 billion by 2032, exhibiting a CAGR of 30.5% during the forecast period. The United States captures the largest machine learning market size, worth $30.62bn, which is higher compared to other countries.
With the global ML market expected to grow from $26.03 billion in 2023 to $225.91 billion by 2030, these rapid advancements are propelling industries toward higher levels of sophistication.
Machine learning makes our lives easier. When properly trained, they can complete tasks more efficiently than a human. Understanding the possibilities and recent innovations of ML technology is important for businesses so that they can plot a course for the most efficient ways of conducting their business. It is also important to stay up to date to maintain competitiveness in the industry.
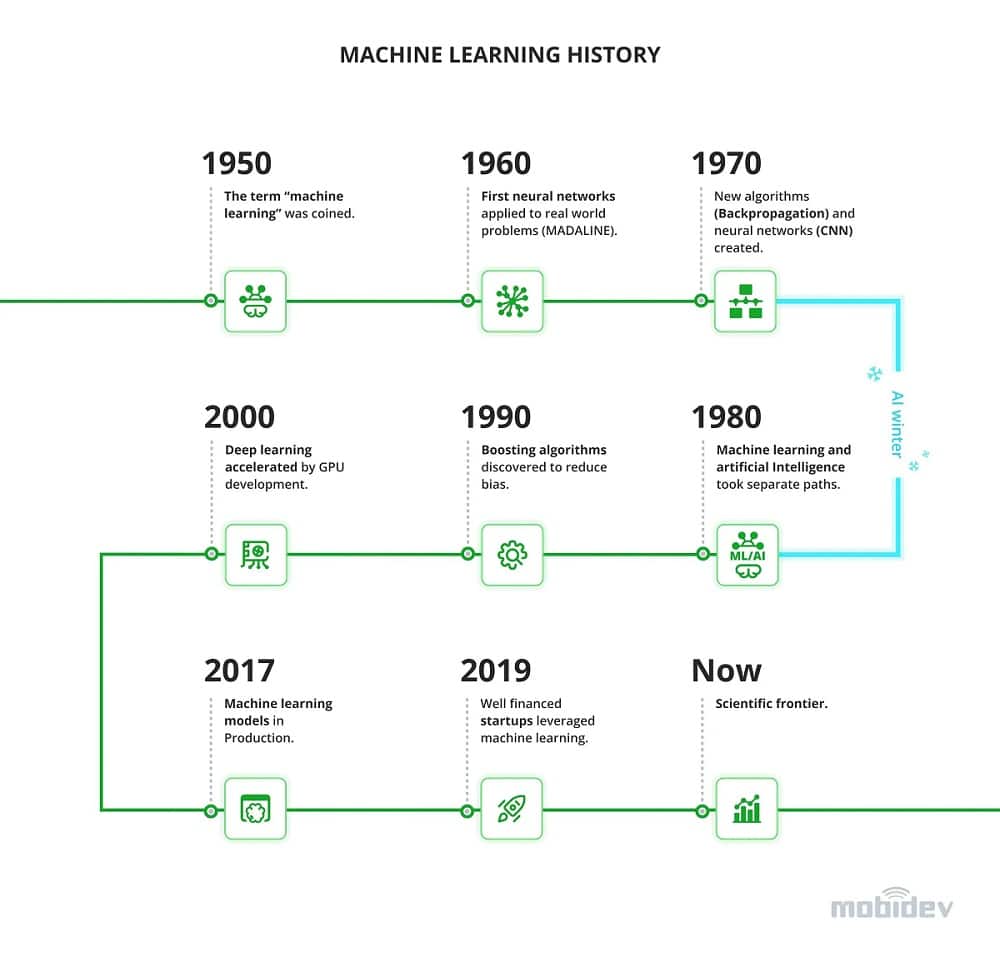
Machine learning models have come a long way before being adopted into production. Here are the 15 Machine learning trends can benefit your business in 2023.
- TinyML
- AutoML
- No-Code Machine Learning
- Machine Learning Operationalization Management (MLOps)
- Generative Adversarial Networks
- Full-stack Deep Learning
- Unsupervised ML
- Reinforcement Learning
- Few Shot, One Shot, & Zero Shot Machine Learning
- Multimodal Machine Learning
- Metaverse
- Machine Learning in Healthcare
- Transformers or Seq2Seq Models
- AI Ethics
- Hyper-automation
1. TinyML:
It can take time for a web request to send data to a large server for it to be processed by a machine learning algorithm and then sent back.
Instead, a more desirable approach might be to use ML programs on edge devices – we can achieve lower latency, lower power consumption, lower required bandwidth, and ensure user privacy.
Another revolutionary transformation in the field of machine learning is tinyML. Tiny Machine Learning was inspired by IoT and the main idea behind it is to enable ML-driven processes on IoT edge devices and devices with low power consumption. A good example of tinyML is a wake command that you give to your smartphone: either “Hey Siri” or “Hey Google”.
The reason behind tinyML is to make machine learning more versatile and to expand its usability. Several years ago, machine learning development required high computational power to handle the processes – but today, tinyML can be implemented to almost any device that has sufficient computing power.
With the rising adoption of IoT technologies, automation, and robotics, embedded systems have gained even more importance, and in the coming years, we might witness a more expanded utilization of this emerging machine-learning phenomenon.
Embedded machine learning (or TinyML) is initially a subfield of machine learning that enables the flawless functioning of machine learning technologies on different devices. Simply put, running machine learning models on embedded devices to make more informed decisions and predictions is termed embedded machine learning.
2. AutoML – Automated machine learning:
Auto-ML brings improved data labeling tools to the table and enables the possibility of automatic tuning of neural network architectures. Evgeniy Krasnokutsky PhD, AI/ML Solution Architect at MobiDev, explains: “Traditionally, data labeling has been done manually by outsourced labor.
This brings in a great deal of risk due to human error. Since AutoML aptly automates much of the labeling process, the risk of human error is much lower.”
AutoML system allows you to provide the labeled training data as input and receive an optimized model as output. There are several ways of going about this. One approach is for the software to simply train every kind of model on the data and pick the one that works best. A refinement of this would be for it to build one or more ensemble models that combine the other models, which sometimes (but not always) gives better results.
You may also like:
Guide To Unsupervised Machine Learning: Use Cases
What Are Transformer Models In Machine Learning
Difference between Machine learning and Artificial Intelligence
Top datasets to actualize machine learning and data training tutorial
How AI and Machine Learning Will Affect Machining
What Is Machine Learning and Where to Find the Best Courses?
3. No-code machine learning and AI
No-code ML is exactly what it sounds – it’s the process of building ML applications without the need to do excessive coding. Instead, you can use a drag-and-drop visual interface to assemble a machine learning application that would satisfy most of your requirements.
No-code ML comes from no-code software development. This concept is relatively new and was introduced as a way to shorten the development time and minimize the needed efforts. Instead of spending hours on manual code writing, users can use specialized programs and “construct” software applications instead of writing them from scratch. And while you can say that machine learning is too complex to be used in a drag-and-drop manner, this development method is already here and is becoming quite popular.
The main reasons behind the use of no-code ML are:
- Faster development and implementation: no-code ML development is much faster than traditional one;
- More affordable: if comparing no-code ML and traditional machine learning development, no-code development comes at a much lower cost;
- Simple and clear interface: no-code development does not require high technical skills from the user and offers a very intuitive and clear interface to work with.
4. MLOps – Machine Learning Operationalization Management
Next in the list of machine learning trends is MLOps. As the name implies, MLOps was inspired by the DevOps methodology. If we address the definition, MLOps is a set of practices for transparent and seamless collaboration of data scientists (“development”) and operational specialists (“operations”).
Before the introduction of MLOps, machine learning development has always been associated with certain challenges, like scalability, development of proper ML pipelines, management of sensitive data at a scale, and communication between the teams. MLOps is aimed to resolve these issues by introducing standard practices to ML applications deployment.
While the phases of MLOps are pretty much the same as phases of traditional ML development, MLOps brings more transparency, eliminates communication gaps, and allows better scaling due to business objective-first design. You can say that with MLOps, you pay much more attention to the process of data collection and cleaning as well as to model training and validation. Hence, enterprises with an acute need for scalability will most definitely benefit from the deployment of the MLOps approach.
5. Generative adversarial networks (GANs)
GAN is kind of a buzzword these days but do you really know the meaning behind it? If not, let’s quickly explain what a generative adversarial network means.
Generative modeling is an unsupervised learning task in machine learning that involves automatically discovering and learning the regularities or patterns in input data in such a way that the model can be used to generate or output new examples that plausibly could have been drawn from the original dataset.
GANs are a clever way of training a generative model by framing the problem as a supervised learning problem with two sub-models: the generator model that we train to generate new examples, and the discriminator model that tries to classify examples as either real (from the domain) or fake (generated). The two models are trained together in a 6. zero-sum game, adversarial, until the discriminator model is fooled about half the time, meaning the generator model is generating plausible examples.
6. Full-stack Deep Learning:
A large demand for “full-stack deep learning” results in the creation of libraries and frameworks that help engineers to automate some shipment tasks and education courses that help engineers to quickly adapt to new business needs.
7. Unsupervised machine learning
Another big thing that we will see in 2022 machine learning trends is unsupervised learning. Again, it’s easy to guess its meaning by its name: unsupervised learning means there is no human intervention in the machine learning process. Instead, the ML model receives unlabelled data and is free to draw any conclusions based on it.
The biggest difference between supervised learning and unsupervised learning is the data. With supervised learning, the data is labeled, meaning people already prepared it for the ML model. With unsupervised learning, the data is unlabelled, meaning it does not have any labels and is not separated into groups or categories. So why would you allow an ML model to be so independent about working with data?
8. Reinforcement Learning
In machine learning, there are three paradigms: supervised learning, unsupervised learning, and reinforcement learning. In reinforcement learning, the machine learning system learns from direct experiences with its environment. The environment can use a reward/punishment system to assign value to the observations that the ML system sees. Ultimately, the system will want to achieve the highest level of reward or value, similar to positive reinforcement training for animals.
This has a great deal of application in video game and board game AI. However, when safety is a critical feature of the application, reinforcement ML may not be the best idea. Since the algorithm comes to conclusions with random actions, it may deliberately make unsafe decisions in the process of learning. This can endanger users if left unchecked. There are safer reinforcement learning systems in development to help with this issue that take safety into account for their algorithms.
You may also like:
Also see:
Top 20 Artificial Intelligence Platforms for 2025
Difference between Machine learning and Artificial Intelligence
Artificial Intelligence: Automating Hiring Process For Businesses!
Top 5 Hidden Artificial Intelligence Technology
Artificial Intelligence: What Can We Expect Next?
9. Few Shot, One Shot, & Zero Shot Learning
Data collection is essential for machine learning practices. However, it is also one of the most tedious tasks and can be subject to error if done incorrectly. The performance of the machine learning algorithm heavily depends on the quality and type of data that is provided. A model trained to recognize various breeds of domestic dogs would need new classifier training to recognize and categorize wild wolves.
Few shot learning focuses on limited data. While this has limitations, it does have various applications in fields like image classification, facial recognition, and text classification. Although not requiring a great deal of data to produce a usable model is helpful, it cannot be used for extremely complex solutions.
Likewise, one shot learning uses even less data. However, it has some useful applications for facial recognition. For example, one could compare a provided passport ID photo to the image of a person through a camera. This only requires data that is already present and does not need a large database of information.
Zero shot learning is an initially confusing prospect. How can machine learning algorithms function without initial data? Zero shot ML systems observe a subject and use information about that object to predict what classification they may fall into. This is possible for humans. For example, a human who had never seen a tiger before but had seen a housecat would probably be able to identify the tiger as some kind of feline animal.

10. Multimodal Machine Learning
Multimodal AI, or Multimodal Machine learning, is an emerging trend with the potential to revolutionize the entire AI and machine learning in the business landscape.
Simply put, Multimodal machine learning is primarily a vibrant multi-disciplinary research field that suggests that the world around us can be experienced in multiple ways (called modalities). Thus, the technology aims to build computer agents with more innovative capabilities, from understanding, reasoning, and learning to leverage multiple communicative modalities, including linguistic, acoustic, visual, tactile, and physiological perceptions.
11. Metaverse
Moving into Industry 4.0, the line between our physical and virtual lives continues to blur, leading businesses to another potential technology of the digital landscape – Metaverse.
As Metaverse proffers unprecedented ways for businesses to interact and collaborate with end-users virtually, in addition to supporting an entirely new virtual economy where users can engage in numerous brand activities, tapping into the Metaverse will increase customer engagement, thus resulting in enhanced acquisition and growth.
12. Machine Learning in Healthcare
We all might agree that healthcare is an ever-evolving industry. New technologies and tools are introduced constantly to pace the entire healthcare industry and its functioning.
As the ability to find and analyze patterns and insights by leveraging machine learning in healthcare gains traction and global adoption, in 2023-24, healthcare providers will have access to many more opportunities of taking a predictive approach to building a unified system empowering improved diagnosis, drug discovery, efficient patient management, care delivery processes.
13. Transformers or Seq2Seq Models
Another AI and Machine learning trend that we will witness rising is Transformers, a.k.a Seq2Seq models. Seq2Seq models are primarily a type of artificial intelligence architecture that enables seamless transduction (or transformation) of data using an encoder and decoder and then gives out another output of the data in the form of an entirely different sequence.
Simply put, transformers are widely utilized in natural language processing tasks and analysis of the sequence of words, letters, and time series, to cater to complex Machine Language problems like Device Translation, Question Answering, creating Chatbots, Text Summarization, etc.
14. AI Ethics
The EU AI Act. The American Data Privacy and Protection Act. The Securing Open Source Software Act. The number of proposed regulations around artificial intelligence is rising rapidly, signaling that the days of companies self-policing their AI/ML projects (or not policing them at all) are coming to an end. Gartner predicts that by 2025 regulations will force companies to focus on AI ethics, transparency and privacy.
15. Hyper-automation
Hyper-automation is another prediction for 2023 by Gartner elaborates on the rising need to become sustainable by moving towards automation and adapting to new technologies and tools. And since automating mundane tasks and complex business operations will require data, patterns, and analysis, workplace innovation will certainly only be possible by employing AI and machine learning in business. As machine learning models become more complex, the demand for high-performance CPUs continues to rise, enabling faster computations and real-time data processing. Additionally, precise calibration services are essential to ensure that both hardware and algorithms operate at peak efficiency, minimizing errors and optimizing performance across various industries.
Sources: mobidev.biz , coppermobile.com
(The post was update on 22 Dec 2025)
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...

7 Top Autonomous AI Pentesting Platforms in 2026
June 10, 2026Autonomous penetration testing is becoming one of the most important changes in ...