How DevOps Can Take Data Science to the Next Level
Big data is all about advanced analytics at extreme scales. Data scientists are, among many things, one of the key application developers for this new age. Quite often, the statistical models they build become production assets that must scale with performance commensurate to the volume, velocity, and variety of the business analytic workloads.
However, most data scientists are, at heart, statistical analysts. While conducting their deep data explorations, they may not be focusing on their downstream production performance of the analytic models they build and refine. If the regression, neural-network, or natural language processing algorithms they’ve incorporated don’t scale under heavy loads, the models may have to be scrapped or significantly reworked before they can be considered production-ready.
Here’s where devops can assist. Devops is a software development method that stresses collaboration and integration between developers and operations professionals. It’s not yet in the core vocabulary of business data scientists, but it should be. Intensifying performance requirements on advanced analytics will bring greater focus on the need for rapid, thorough performance testing of analytic models in production-grade environments. As these needs grow, the mismatches in perspective and practice between data scientists (who may treat performance as an afterthought) and IT administrators (who live and breathe performance) will become more acute.
What is DevOps?
DevOps is a set of practices that brings together software development (Dev) and IT operations (Ops) to shorten the development lifecycle and deliver high-quality software continuously. It complements Agile methods by emphasizing automation, collaboration, and rapid feedback loops from code to production. At its core, DevOps is the union of people, processes, and technology working in sync to consistently deliver value to customers.
What are the Fundamentals Of DevOps?
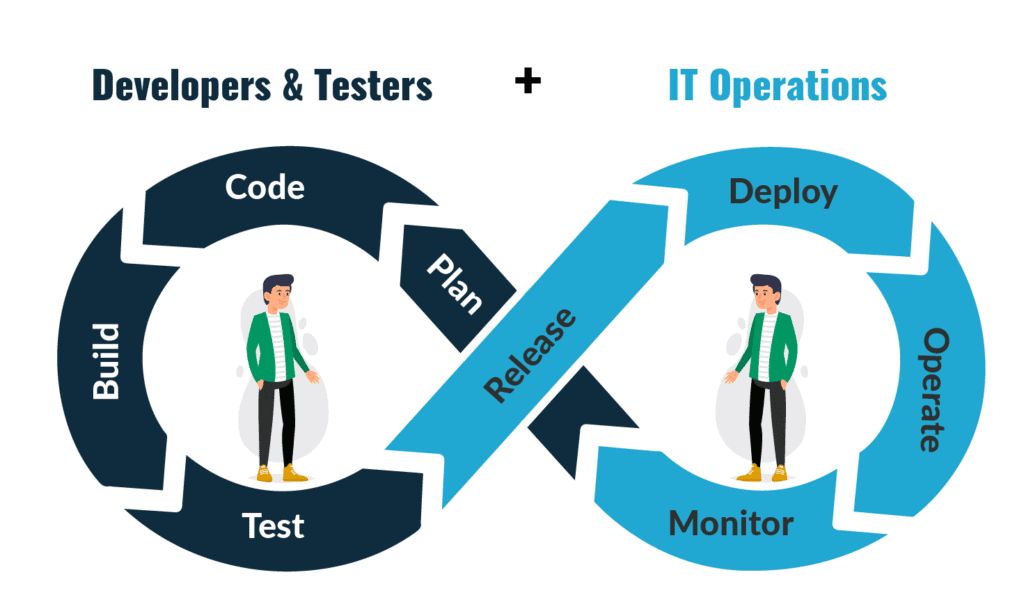
- Code: The first step in the DevOps life cycle is coding, where developers build the code on any platform
- Build: Developers build the version of their program in any extension depending upon the language they are using
- Test: For DevOps to be successful, the testing process must be automated using any automation tool like Selenium
- Release: A process for managing, planning, scheduling, and controlling the build in different environments after testing and before deployment
- Deploy: This phase gets all artifacts/code files of the application ready and deploys/executes them on the server
- Operate: The application is run after its deployment, where clients use it in real-world scenarios
- Monitor: This phase helps in providing crucial information that basically helps ensure service uptime and optimal performance
- Plan: The planning stage gathers information from the monitoring stage and, as per feedback, implements the changes for better performance
Data science has become a core driver of innovation, helping organizations uncover insights, automate decisions, and build intelligent products. However, many data science initiatives struggle to move beyond experimentation into reliable, scalable production systems. This is where DevOps plays a critical role.
By applying DevOps principles and practices, organizations can bridge the gap between data science and production, enabling faster delivery, better collaboration, and more dependable AI and analytics solutions.
The Gap Between Data Science and Production
Data science teams often work in isolated environments, focusing on exploration, model building, and experimentation. While this approach is effective for discovery, it creates challenges when models need to be deployed, monitored, and maintained at scale.
Common challenges include:
- Inconsistent environments between development and production
- Manual and error-prone deployment processes
- Lack of version control for data and models
- Difficulty monitoring model performance over time
Without a structured operational framework, even the best models can fail to deliver real business value.
DevOps as the Missing Link
DevOps introduces a culture of collaboration, automation, and continuous improvement. When applied to data science—often referred to as MLOps or DataOps—DevOps practices help streamline the entire lifecycle of data-driven applications.
Key DevOps principles that enhance data science include:
- Continuous integration and deployment (CI/CD)
- Infrastructure as code (IaC)
- Automation and reproducibility
- Monitoring and feedback loops
Together, these principles ensure that data science solutions are reliable, scalable, and production-ready.
Faster Model Development and Deployment
DevOps automation accelerates the journey from experimentation to deployment. With CI/CD pipelines, data scientists can automatically test, validate, and deploy models whenever changes are made.
Benefits include:
- Faster iteration and experimentation
- Reduced deployment errors
- Consistent environments across teams
- Shorter time-to-value for AI initiatives
This speed allows organizations to respond quickly to changing data and business requirements.
Improved Collaboration Between Teams
DevOps breaks down silos between data scientists, engineers, and IT operations. Shared workflows, tools, and responsibilities encourage collaboration throughout the model lifecycle.
This collaboration leads to:
- Better alignment between business goals and technical solutions
- Clear ownership of models and data pipelines
- Faster issue resolution and continuous improvement
As a result, data science becomes a team-driven effort rather than an isolated function.
Scalability and Reliability at Enterprise Scale
DevOps practices enable data science systems to scale effortlessly. Using containerization and cloud-native infrastructure, teams can deploy models that handle large volumes of data and high user demand.
Additionally, monitoring and logging tools provide visibility into:
- Model performance and drift
- Data quality issues
- System reliability and uptime
This ensures data science solutions remain accurate and dependable over time.
Better Governance and Reproducibility
Version control for code, data, and models is essential for reproducibility and compliance. DevOps workflows enforce best practices such as automated testing, audit trails, and controlled releases.
This improves:
- Model transparency and trust
- Regulatory compliance
- Risk management and accountability
Well-governed systems build confidence in AI-driven decision-making.
The Rise of MLOps and DataOps
DevOps has given rise to specialized practices like MLOps and DataOps, which extend DevOps concepts to machine learning and data pipelines. These approaches focus on managing data, models, and workflows as production-grade assets.
By adopting MLOps and DataOps, organizations can:
- Operationalize AI at scale
- Reduce technical debt
- Maximize the return on data science investments
Conclusion
DevOps has the power to take data science to the next level by transforming experimental models into scalable, reliable, and impactful solutions. By embracing automation, collaboration, and continuous delivery, organizations can unlock the full potential of their data science efforts.
In a world where data and AI are central to competitive advantage, integrating DevOps with data science is no longer optional—it’s essential.
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...