Top datasets to actualize machine learning and data training tutorial
“A Breakthrough in machine learning would be worth ten Microsofts” – Bill Gates
Yes, due to many obvious reasons, Bill Gates is right and we will prove it in this blog.
Though the term, machine learning was tossed by Arthur Samuel in 1959 while working at the IBM, the actual serviceability of it started popping up after 2010. So, Dave Waters compares the advancement of machine learning with the baby – “A baby learns to crawl, walk and then run. We are in the crawling stage when it comes to applying machine learning.”
Recently, machine learning market has witnessed exceptional growth and it is estimated to reach $21 billion by 2024. The reason why every expert is quoting machine learning as the future of all businesses is because of its versatility. From the mining industry to supply chain, marketing, recruitment, mobile app development, aviation, film making, machine learning is streamlining the sales -cycle and letting business owners derive many financial benefits.
However, developing applications which run on the machine learning technology is not as easy as pie. Data scientists have to decode many challenges to actualize machine learning. One of the biggest challenges is finding suitable dataset. Because, without finding a suitable dataset and training machine learning algorithm on it, machine learning can never come to life.
Thus looking at the urgency, I will talk about everything about datasets and how to actually use datasets, in this blog. I will also share a tutorial showing how to train a machine learning algorithm using a dataset. (For that, I will train Genetic Algorithm on KDD dataset.)
What is a dataset?
To understand datasets more rationally, we have to understand the working method of machine learning including the concept of ‘training data’.
Machine learning is the technology in which algorithms perform specific tasks without human command. The one major task machine learning algorithms can easily satisfy is predication. To do predication, algorithms make rules and to make rules, algorithms rely on big data. Still confused?
Consider the brain of a football player. Throughout his career, his brain has collected many data related to leg movements of goal-keepers and their next action based on their leg movements. Using this data, his brain makes so many rules; I.e if goalkeeper moves his leg to left, he will jump to the right. These rules are being executed in real-time while he is playing football; his brain predicts the next action of goal-keepers based on his leg movement, using the rules his brain has made ‘using’ collected data. Meaning, without the data (datasets), his brain can never ever make rules which do predication.
In the more specific term, the dataset is nothing but the collection of many attributes of a topic in a known file format. Machine learning algorithms take this dataset as input and give us relationships between different attributes of the dataset as an output. This process is known as the data-training and the output of data-training is generally considered as the rules. After this process, the machine learning algorithm becomes smart enough to execute any task by itself, by scanning each real-time data and comparing it with the rules. Rules are always in ‘if…then’ format (if X=x, Y=y and Z=z… then A=a).
Properties of datasets
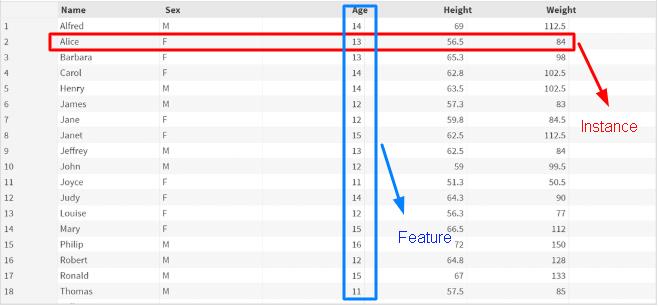 Datasets are the combination of rows and columns. But when it comes to datasets which are being used for machine learning, even an easy concept like rows and columns becomes complex!
Datasets are the combination of rows and columns. But when it comes to datasets which are being used for machine learning, even an easy concept like rows and columns becomes complex!
Here, it is worth mentioning that, datasets can contain images, videos, and text. But for better understanding, we are only talking about the datasets that entertain text data.
Feature:
As you can see in the image, the Feature is a single column of data. When you apply a machine learning algorithm on the dataset, the algorithm takes some Features as the input and some as the output, but not by itself. You have to write code to define input Features and output Features according to your need. The input Features are called predictors and using these predictors, the algorithm predicts and makes rules.
Instance:
The Instance isn’t as complex as Feature. It is a single row of data. Unlike Feature, Instance isn’t restricted to one attribute of data only. Instead, it stores the value of all attributes.
Data types:
Values of all attributes have certain data type and in many cases, attributes of the single dataset have different data types. It can be string, dates, times and more complex types. But to train machine learning algorithm or model efficiently, it is advisable to reduce data types to real or categorical values.
How to select the optimal dataset to train a machine learning model?
Considering the fact that dataset is a fundamental need for a machine learning model to be trained or to make rules, one should not overlook the optimal discovery of the dataset for his machine learning project.
You can train your machine learning model on your own collected data or on the data which is available online. In both cases, you have to consider a few things which are,
● Source of the data
This is perhaps the most crucial thing – you need to validate the source of the datasets. Since your machine learning application will solely work on the rules it makes using dataset, you just cannot afford fake datasets. To always end up choosing genius datasets, prefer some popular data science journals. You can also prefer datasets provided by universities and even governments.
Kaggle and UCI Machine Learning Repository are the two verified open dataset finders.
● Relativity of the dataset with your purpose
If you are developing a machine learning-enabled sales prediction system for grocery stores, then none of the datasets will justify your need, except the datasets of the grocery store. To check the relativity of the dataset with your purpose, pay heed to the attributes of the dataset. They reveal everything about the dataset.
● Size of the data
Like a car cannot drive more kilometre with less fuel, a machine learning algorithm cannot make rules with fewer data. However, since all datasets hold enough number of Instances, the size of the data won’t be an issue. But if you are planning to train a machine learning algorithm based on your own collected data, then it is recommended to choose dataset which has at least more than 1000 Instances. And when you are choosing the large dataset, you need to consider the computation power of your system.
Most popular and usable datasets
Following are some hand-picked and very useful datasets available online for your machine learning applications.
1) QuandI
QuandI dataset is the premium source of financial and economical data. It contains the data of the world’s top hedge funds, asset managers, and investment banks. This dataset is very useful to develop machine-learning enabled FinTech apps which have machine learning models to predict economic indicators or stock price.
2) ImageNet
If you wish to train your machine learning model for the image recognition purpose, there is not a better choice than ImageNet. ImageNet dataset stores images in Wordnet hierarchy. It contains 100,000 phrases and 1000 images for each phrase. The total number of records ImageNet dataset is owning is more than 15,00,000.
3) VisualQA
 Many times, the machine learning module has to identify the characteristics of the image with the help of question-answer model. To satisfy such requirement, VisualQA is an unswappable choice. It stores over 250000 images and 5.4 questions on average per image. The size of the VisualQA dataset is 25GB.
Many times, the machine learning module has to identify the characteristics of the image with the help of question-answer model. To satisfy such requirement, VisualQA is an unswappable choice. It stores over 250000 images and 5.4 questions on average per image. The size of the VisualQA dataset is 25GB.
4) SVHN
 The Street View House Numbers (SVHN) dataset is very serviceable for developing an autonomous vehicle. This dataset contains real-world images for the purpose of object detection. There are more than 600000 images in this dataset which occupy 2.5GB of space.
The Street View House Numbers (SVHN) dataset is very serviceable for developing an autonomous vehicle. This dataset contains real-world images for the purpose of object detection. There are more than 600000 images in this dataset which occupy 2.5GB of space.
5) Chicago taxi trips data
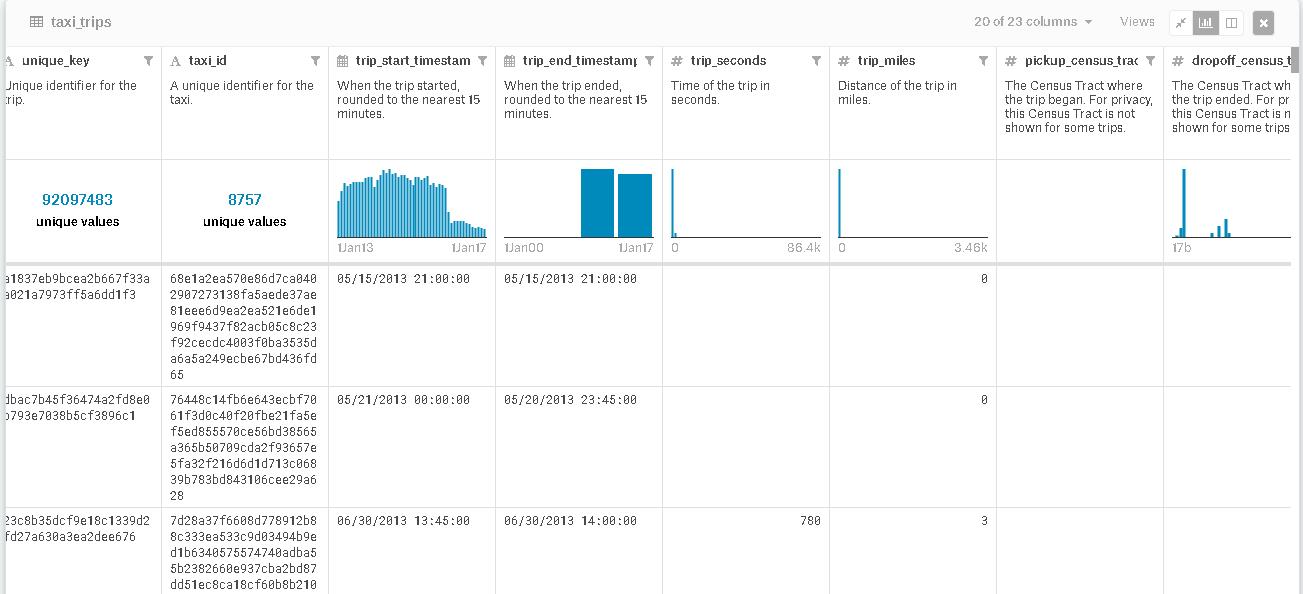 If you want to develop a taxi app which works on machine learning technique, you need to train the algorithm on dataset and Chicago taxi trips data set is the most suitable dataset for your purpose. It includes the data from 2013 to present. It reveals every detail of the trip including the distance and time which can take your machine learning-enabled taxi app next level.
If you want to develop a taxi app which works on machine learning technique, you need to train the algorithm on dataset and Chicago taxi trips data set is the most suitable dataset for your purpose. It includes the data from 2013 to present. It reveals every detail of the trip including the distance and time which can take your machine learning-enabled taxi app next level.
6) Chrome user experience dataset
Chrome user experience dataset discloses data related to user reviews. It has columns like origin, effective_connection_type, form_factor, first_paint, first_contentful_paint, and dom_content_loaded. With this, you can train your machine learning model to sustain the user experience of a web application.
7) Oxford’s Robotic Car
A robotic car stored road data of Oxford, the UK with its over 1000 repetitions on the same routes which are now available for free to download. This dataset has details of weather, traffic, pedestrians including how sensors work in open world.
8) KDD Cup dataset
KDD is the most verified dataset to train the machine learning module to identify cyberattack in real-time. It contains internet packages data with the value of each attribute of the packages and type of attacks. The best part of this dataset is that almost all attributes are having a real data type.
We will now understand the concept of data-training and the use of machine learning in real-life by training a machine learning algorithm with KDD Cup dataset.
Data-training in action, building Intrusion Detection System (IDS) with KDD Cup dataset and Genetic Algorithm
I will try to keep this learning really straightforward. And for that, I will explain every concept of IDS separately.
1. Intrusion Detection system: It is just a computer program which scans every incoming package on the network and compares the value of package with the rules to identify whether it is a malicious package or not. If IDS finds that the incoming package is malicious, it alerts the admin with potential attack type.
2. Rule Engine: Rule engine is another computer program which is written on the methodology of the Genetic Algorithm. This program (Genetic Algorithm) takes KDD dataset as input and makes rules which it uploads to IDS. This is the heart of the IDS.
3. KDD Cup dataset: It contains historic data of cyber attacks and what were the values of different attributes of the internet packages at the time of attack. Following are the attributes of a single package.

4.Genetic Algorithm
Genetic algorithm is the machine learning algorithm, belonged to larger part of evolutionary algorithms. It works based on the idea of natural selection and genetics. Here is how.
It takes dataset (in our case it is KDD) as the input and compares the value of the dataset with the randomly generated values which are called population. Based on a number of same values presented in both dataset and population, it finds the fitness function. Fitness function is nothing but the value to evaluate how close a given solution is to the optimum solution of the desired problem. Once it finds the fitness function of all Instances, it only picks the Instances which are having high fitness function, beyond a set threshold. It then does the Crossover and Mutation. In Crossover, it takes values from two Instances and makes single Instance and in Mutation, it swaps the values of Instance it gets after Crossover.
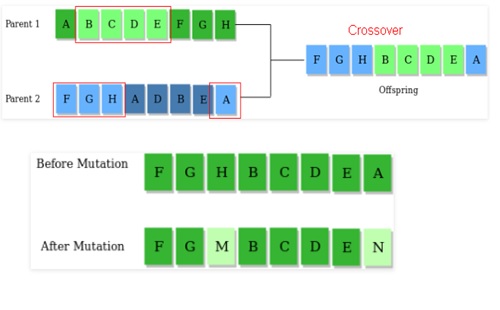 The algorithm now takes the output of the Mutation as the input, generates another population, compares taken input with generated population, define fitness function, does Crossover and Mutation. The algorithm keeps doing this until it does not get the highest ever fitness function. And when it gets highest fitness function, the values of the Insurance having highest fitness function are considered as a solution to our problem. In other words, they are the ‘rules’.
The algorithm now takes the output of the Mutation as the input, generates another population, compares taken input with generated population, define fitness function, does Crossover and Mutation. The algorithm keeps doing this until it does not get the highest ever fitness function. And when it gets highest fitness function, the values of the Insurance having highest fitness function are considered as a solution to our problem. In other words, they are the ‘rules’.
Here is the example of the rule: If Duration = “1”, Protocol Type = “3”, service = “2”, ……..” then Attack type = “DOS”
(all values of the attributes has already been converted into real)
Now, imagine what kind of benefits you can derive if you predict the attack, predict the business sale, predict the stock price and predict the human death date!
In the nutshell
Hence it is proved, A Breakthrough in machine learning would be worth ten Microsofts!
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...