5 Reasons to Choose Parquet for Spark SQL
It is well-known that columnar storage saves both time and space when it comes to big data processing. Parquet, for example, is shown to boost Spark SQL performance by 10X on average compared to using text, thanks to low-level reader filters, efficient execution plans, and in Spark 1.6.0, improved scan throughput!
To see the power of Parquet, we pick 24 TPC-DS-derived queries (out of 99 because some queries simply fail to run with flat CSV data files at 1TB scale factor. More on this below.) from the spark-perf-sql test kit for comparison. The queries represent all categories in TPC-DS: reporting, ad hoc, iterative and data mining. We also make sure to include both short (queries 12 and 91) and long-running queries (queries 24a and 25), and queries known to use 100% of CPU (query 97).
We use a 6-node on-prem Cisco UCS cluster similarly configured per Cisco Validated Designs. We tune the underlying hardware so there is no network or disk IO bottlenecks in any tests. The focus is to find differences in performance running these queries simply with text and Parquet storage formats in Spark 1.5.1 and in the just-released Spark 1.6.0. The total Spark working memory is 500GB. The TPC-DS scale factor is 1TB.
What is Apache Spark SQL?
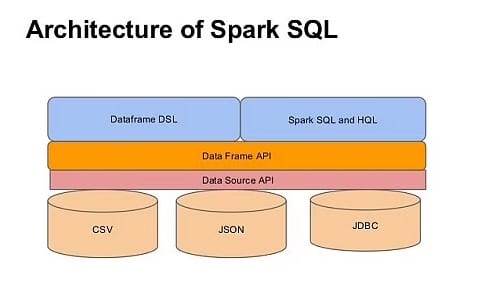
Spark SQL is a Spark module for structured data processing. It provides a programming abstraction called DataFrames and can also act as a distributed SQL query engine. It enables unmodified Hadoop Hive queries to run up to 100x faster on existing deployments and data. It also provides powerful integration with the rest of the Spark ecosystem (e.g., integrating SQL query processing with machine learning).
Spark SQL brings native support for SQL to Spark and streamlines the process of querying data stored both in RDDs (Spark’s distributed datasets) and in external sources. Spark SQL conveniently blurs the lines between RDDs and relational tables. Unifying these powerful abstractions makes it easy for developers to intermix SQL commands querying external data with complex analytics, all within in a single application. Concretely, Spark SQL will allow developers to:
- Import relational data from Parquet files and Hive tables
- Run SQL queries over imported data and existing RDDs
- Easily write RDDs out to Hive tables or Parquet files
Spark SQL also includes a cost-based optimizer, columnar storage, and code generation to make queries fast. At the same time, it scales to thousands of nodes and multi-hour queries using the Spark engine, which provides full mid-query fault tolerance, without having to worry about using a different engine for historical data.
- Spark SQL is much faster with Parquet!
The chart below compares the sum of all execution times of the 24 queries running in Spark 1.5.1. Queries taking about 12 hours to complete using flat CVS files vs. taking less than 1 hour to complete using Parquet, a 11X performance improvement.
- Spark SQL works better at large-scale with Parquet
Poor choice of storage format often cause exceptions that are difficult to diagnose and fix. At 1TB scale factor for example, at least 1/3 of all runnable queries failed to complete using flat CSV files, but they all completed using Parquet files.
- Less disk IO
Parquet with compression reduces your data storage by 75% on average, i.e., your 1TB scale factor data files will materialize only about 250 GB on disk. This reduces significantly input data needed for your Spark SQL applications. But in Spark 1.6.0, Parquet readers used push-down filters to further reduce disk IO. Push-down filters allow early data selection decisions to be made before data is even read into Spark.
- Higher scan throughput in Spark 1.6.0
The Databricks’ Spark 1.6.0 release blog mentioned significant Parquet scan throughput because a “more optimized code path” is used. To show this in real world, we ran query 97 in Spark 1.5.1 and in 1.6.0 and captured nmon data. The improvement is very obvious.
- Efficient Spark execution graph
In addition to smarter readers such as in Parquet, data formats also directly impact Spark execution graph because one major input to the scheduler is RDD count. In our example where we run the same query 97 on Spark 1.5.1 using text and Parquet, we got the following execution pattern for the stages. Read more
Accessing Parquet Files From Spark SQL Applications
Spark SQL supports loading and saving DataFrames from and to a variety of data sources and has native support for Parquet. For information about Parquet, see Using Apache Parquet Data Files with CDH.
To read Parquet files in Spark SQL, use the SQLContext.read.parquet(“path”) method.
To write Parquet files in Spark SQL, use the DataFrame.write.parquet(“path”) method.
To set the compression type, configure the spark.sql.parquet.compression.codec property:
sqlContext.setConf(“spark.sql.parquet.compression.codec”,”codec”)
The supported codec values are: uncompressed, gzip, lzo, and snappy. The default is gzip.
Currently, Spark looks up column data from Parquet files by using the names stored within the data files. This is different than the default Parquet lookup behavior of Impala and Hive. If data files are produced with a different physical layout due to added or reordered columns, Spark still decodes the column data correctly. If the logical layout of the table is changed in the metastore database, for example through an ALTER TABLE CHANGE statement that renames a column, Spark still looks for the data using the now-nonexistent column name and returns NULLs when it cannot locate the column values. To avoid behavior differences between Spark and Impala or Hive when modifying Parquet tables, avoid renaming columns, or use Impala, Hive, or a CREATE TABLE AS SELECT statement to produce a new table and new set of Parquet files containing embedded column names that match the new layout.
What’s new in Apache Spark 3.2.0
Datetime rebasing in read options
Apache Spark 3.0 changed the hybrid Julian+Gregorian calendar to a more standardized Proleptic Gregorian Calendar. At this occasion, the framework also got the spark.sql.legacy.(parquet|avro).datetimeRebaseModeInRead configuration property to keep the backward compatibility (although, it was also possible to fail the reader by setting the “exception” value).
However, the rebase option was available globally, at the SparkSession level. Starting fro, Apache Spark 3.2.0, you can use it locally, at a data source level:
Column indexes in Parquet
Column indexes aren’t new in Apache Parquet, but Apache Spark hasn’t supported them in the vectorized reader. At first glance, it sounds like huge work involving many code changes. However, it happens that implementing the column indexes support for that reader was “just” the matter of using an appropriate method from Apache Parquet dependency!
public class ParquetFileReader implements Closeable {
// ...
/**
* Reads all the columns requested from the row group at the current file position. It may skip specific pages based
* on the column indexes according to the actual filter. As the rows are not aligned among the pages of the different
* columns row synchronization might be required. See the documentation of the class SynchronizingColumnReader for
* details.
*
* @return the PageReadStore which can provide PageReaders for each column
* @throws IOException
* if any I/O error occurs while reading
*/
public PageReadStore readNextFilteredRowGroup() throws IOException {
// ...
/**
* Reads all the columns requested from the row group at the current file position.
* @throws IOException if an error occurs while reading
* @return the PageReadStore which can provide PageReaders for each column.
*/
public PageReadStore readNextRowGroup() throws IOException {Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...