Anatomy of a MapReduce Job
Hadoop Ecosystem and MapReduce
There is an extensive list of products and projects that either extend Hadoop’s functionality or expose some existing capability in new ways. For example, executing SQL-like queries on top of Hadoop has spwaned several products. Facebook started this whole movement when it created HiveQL, an SQL-like query language. HBase and Accumulo are both NoSQL databases (i.e., semi-structured table storage) built on top of Hadoop. It is very common to see users writing MapReduce jobs that fetch data from and write data into a NoSQL storage like HBASE or Accumulo. Finally an Apache project called Pig provides an abstraction layer with the help of scripts in the language Pig Latin, which are translated to MapReduce jobs. Other examples of projects built on top of Hadoop include Apache Sqoop, Apache Oozie, and Apache Flume . Figure 1 shows some of the products built upon and that complement Hadoop.
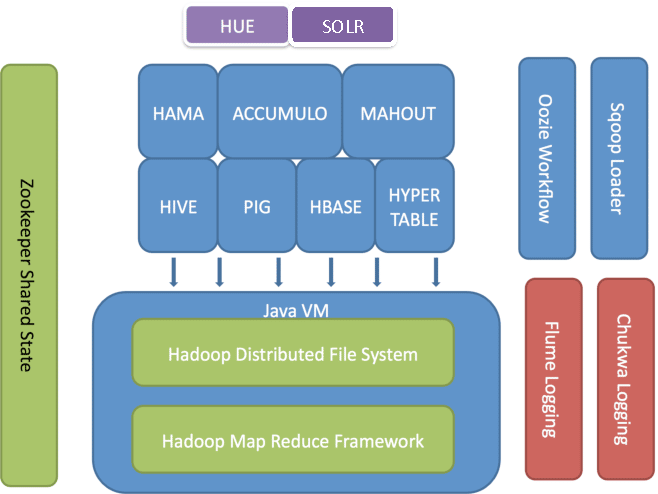
Hadoop ecosystem with multitude of products.
The below Fig. shows the data flow through the map and reduce phases. We discuss the input splits and the different phases of a MapReduce job in greater detail later in this section.
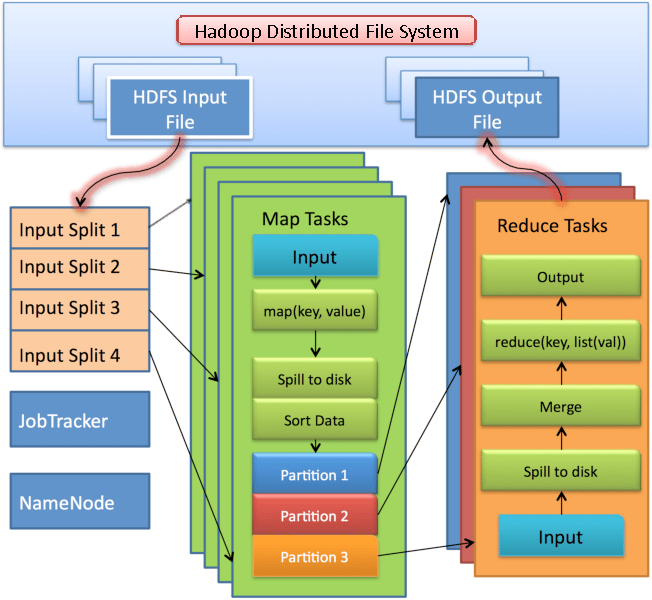
Fig. Hadoop MapReduce Data Flow
A Hadoop MapReduce cluster employs a masterslave architecture where one master node (known as JobTracker) manages a number of worker nodes (known as the TaskTrackers). Hadoop launches a Anatomy of MapReduce job by first splitting (logically) the input dataset into multiple data splits. Each map task is then scheduled to one TaskTracker node where the data split resides. A Task Scheduler is responsible for scheduling the execution of the tasks as far as possible in a data-local manner. A few different types of schedulers have been already developed for the MapReduce environment.
From a bird’s eye view, a anatomy of MapReduce job is not all that complex because Hadoop hides most of the complexity of writing parallel programs for a cluster of computers. In a Hadoop cluster, every node normally starts multiple map tasks (many times depending on the number of cores a machine has) and each task will read a portion of the input data in a sequence, process every row of the data and output a <key, value> pair. The reducer tasks in turn collect the keys and values outputted by the mapper tasks and merge the identical keys into one key and the different map values into a collection of values. An individual reducer then will work on these merged keys and the reducer task outputs data of its choosing by inspecting its input of keys and associated collection of values. The programmer needs to supply only the logic and code for the map() and the reduce() functions. This simple paradigm can solve surprisingly large types of computational problems and is a keystone of the anatomy of mapreduce Job in big data processing revolution.
In a typical Anatomy of MapReduce job, input files are read from the Hadoop Distributed File System (HDFS). Data is usually compressed to reduce file sizes. After decompression, serialized bytes are transformed into Java objects before being passed to a user-defined map() function. Conversely, output records are serialized, compressed, and eventually pushed back to HDFS. However, behind this apparent simplicity, the processing is broken down into many steps and has hundreds of different tunable parameters to fine-tune the job’s running characteristics. We detail these steps starting from when a job is started all the way up to when all the map and reduce tasks are complete and the JobTracker (JT) cleans up the job.
Hadoop MapReduce jobs are divided into a set of map tasks and reduce tasks that run in a distributed fashion on a cluster of computers. Each task work on a small subset of the data it has been assigned so that the load is spread across the cluster.
The input to a MapReduce job is a set of files in the data store that are spread out over the HDFS. In Hadoop, these files are split with an input format, which defines how to separate a files into input split. You can assume that input split is a byte-oriented view of a chunk of the files to be loaded by a map task.
The map task generally performs loading, parsing, transformation and filtering operations, whereas reduce task is responsible for grouping and aggregating the data produced by map tasks to generate final output. This is the way a wide range of problems can be solved with such a straightforward paradigm, from simple numerical aggregation to complex join operations and cartesian products.
Each map task in Hadoop is broken into following phases: record reader, mapper, combiner, Hadoop partitioner. The output of map phase, called intermediate key and values are sent to the reducers. The reduce tasks are broken into following phases: shuffle, sort, reducer and output format. The map tasks are assigned by Hadoop framework to those DataNodes where the actual data to be processed resides. This ensures that the data typically doesn’t have to move over the network to save the network bandwidth and data is computed on the local machine itself so called map task is data local.
 Mapper
Mapper
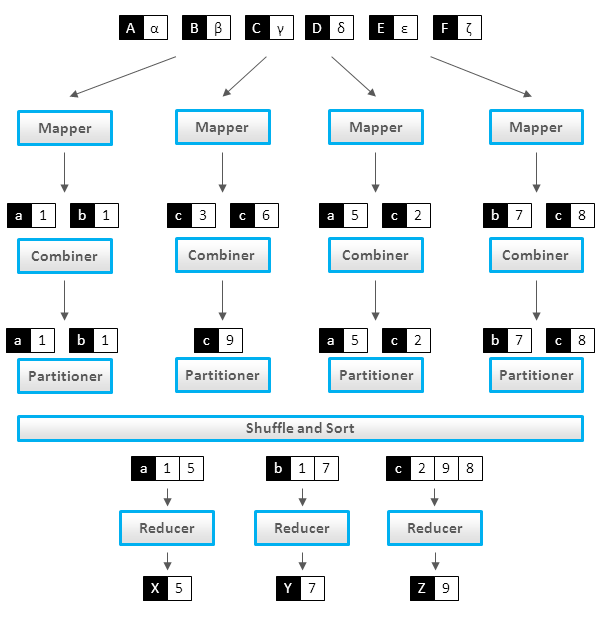
Record Reader:
The record reader translates an input split generated by input format into records. The purpose of record reader is to parse the data into record but doesn’t parse the record itself. It passes the data to the mapper in form of key/value pair. Usually the key in this context is positional information and the value is a chunk of data that composes a record. In our future articles we will discuss more about NLineInputFormat and custom record readers.
Map:
Map function is the heart of mapper task, which is executed on each key/value pair from the record reader to produce zero or more key/value pair, called intermediate pairs. The decision of what is key/value pair depends on what the MapReduce job is accomplishing. The data is grouped on key and the value is the information pertinent to the analysis in the reducer.
Combiner:
Its an optional component but highly useful and provides extreme performance gain of MapReduce job without any downside. Combiner is not applicable to all the MapReduce algorithms but where ever it can be applied it is always recommended to use. It takes the intermediate keys from the mapper and applies a user-provided method to aggregate values in a small scope of that one mapper. e.g sending (hadoop, 3) requires fewer bytes than sending (hadoop, 1) three times over the network. We will cover combiner in much more depth in our future articles.
Partitioner:
The Hadoop partitioner takes the intermediate key/value pairs from mapper and split them into shards, one shard per reducer. This randomly distributes the keyspace evenly over the reducer, but still ensures that keys with the same value in different mappers end up at the same reducer. The partitioned data is written to the local filesystem for each map task and waits to be pulled by its respective reducer.
Reducer
Shuffle and Sort:
The reduce task start with the shuffle and sort step. This step takes the output files written by all of the hadoop partitioners and downloads them to the local machine in which the reducer is running. These individual data pipes are then sorted by keys into one larger data list. The purpose of this sort is to group equivalent keys together so that their values can be iterated over easily in the reduce task.
Reduce:
The reducer takes the grouped data as input and runs a reduce function once per key grouping. The function is passed the key and an iterator over all the values associated with that key. A wide range of processing can happen in this function, the data can be aggregated, filtered, and combined in a number of ways. Once it is done, it sends zero or more key/value pair to the final step, the output format.
Output Format:
The output format translate the final key/value pair from the reduce function and writes it out to a file by a record writer. By default, it will separate the key and value with a tab and separate record with a new line character. We will discuss in our future articles about how to write your own customized output format.
Anatomy of Hadoop MapReduce Execution:
Once we give a MapReduce job the system will enter into a series of life cycle phases:
- Job Submission Phase
- Job Initialization Phase
- Task Assignment Phase
- Task Execution Phase
- Progress update Phase
- Failure Recovery
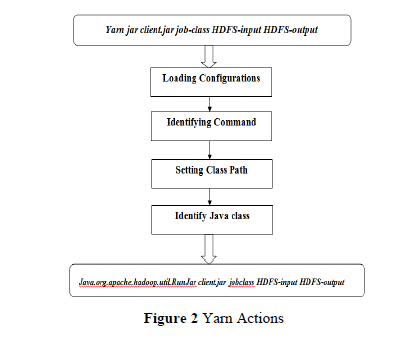
In order to run the MR program the hadoop uses the command-‘yarn jar client.jar job-class HDFS input HDFS-output directory’, where yarn is an utility and jar is the command.Client.jar and job class name written by the developer. When we execute on terminal the Yarn will initiate a set of actions (see figure 2)
- Loading configurations
- Identifying command
- Setting class path
- Identifying the java class corresponding to the jar command
i.e..org.apache.hadoop.util.RunJar.Then it will set the user provided command to “java. Org .apache. hadoop.util. RunJar job-class HDFS-input HDFS-output directory”.
The execution system will create a RunJar class and call the main method (see org. apache.hadoop.util.RunJar GrepCode). Main method checks for the its arguments which are the client.jar and its job class name. Thus yarn will execute the job class (word count)with its arguments as the hdfs input and output. Job class then calls its own main method. The ToolRunner.run() method will call any of the trigger method i.e. submit, jobClient.runjob ,waitForComplition, and this will initiate the MR framework in edge node by checking the mapredsite.xml.
The ‘map reduce.framework.name’ field is visited and pulls the value which can be either YARN, LOCAL, CLASSIC, YARN-TEZ. Corresponding to the value specified a JobRunner instance is created. If the framework is using YARN then the instance created will be RemoteJobRunner, and LocalJobRunner if the value is LOCAL. The instance created then submit the application to the Resource Manager using RPC or Local protocols. Before submitting the application MR framework will create JobSubmitter(JS) instance and initialize the job submission phase of the MR job.
1. Job Submission Phase
The JobSubmitter invoke getNewApplicationId() on Resource Manager to get a new Application id for the job initiated. Then it validates input and output paths given by the user and checks whether the input file and output directory already exist or not. JobSubmitter contact the NameNode and get the metadata .It also compute the input splits ie. How many blocks of data are needed and also creates a shared directory inside Resource Manager with corresponding Application id. JobSubmitter then create a job.xml file which contains the following details of map reduce job, JobClassName,Input,Output,InputFormat,OutputFormat,Number of Splits,,Mapper, Reducer Class,Jar file name etc.. and copy the job.xml to shared directory .Ten copies of client.jar are created and keep the first copy in the shared directory and keeps the remaining nine copies in any configurable nodes in the network. Js submit this application-id to Resource Manager. The workflow is explained as(see figure-3):-
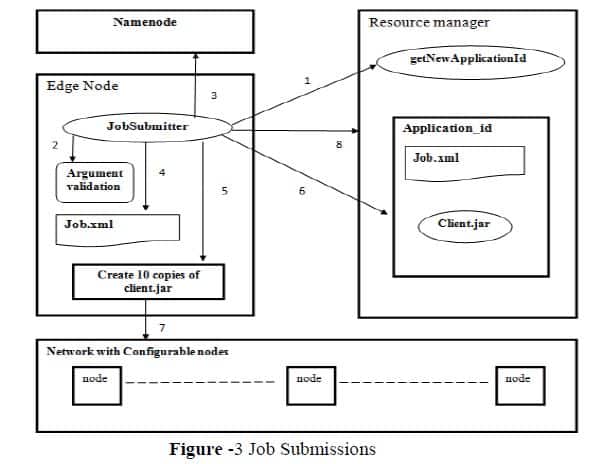
- Generate new application id.
- Validate the user input.
- Gather metadata from NameNode.
- Create job.xml file
- Create ten copies of client.jar.
- Create a shared directory(job.xml,client.jar).
- Keep nine copies of client.jar in Datanodes.
2. Job Initialization
Once the job is submitted by the JS the control will move to the cluster side from edge node. Resource Manager contains a candidate called Application Manager which maintains a queue of application ids submitted by the clients. The default name of the queue is ‘default’. The applications submitted in the queue are scheduled by ‘YARN Scheduler’ .To execute the job an Application Master is required, which cannot be created by YARN Scheduler. So a request is given to the Resource Manager to create Application Master. Resource manager will contact all Node Managers(NM) in the cluster to check the container-0 specification (minimum 2 GB and maximum 20GB).If any Node Manager possesses container-0 specification will respond to RM with a positive signal. In the new generations of Hadoop, NM continuously sends heart beats to the RM with its specifications so it’s possible for the RM to select NM without network overhead.
Resource Manager will identify what type of application we are executing (YARN is not a MapReduce specific platform, it’s a diversified programming approach).Since we are executing MapReduce application type, it wil request the node manager to create JVM in container-0 and deploy MRAppMaster which is a MapReduce specific AppMaster. This AppMaster acts as the leader which manages the execution of the specified job by initiating it with the application id. AppMaster then go and contact the shared directory in the RM to get the job.xml file. It creates Mappers based on number of input splits specified in the file.ie Number of Mappers =Number of input splits. Reducer count is decided by the developer based on the output load and can be specified in job.xml. The Job Initialization phase will come to an end when the mapper ids for the required splits are created and add in the queue. The workflow is explained as (see figure-4):-
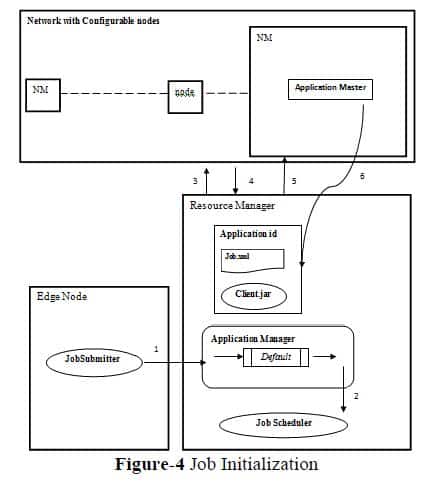
- Add application id into default queue.
- JobScheduler starts scheduling.
- Check with NM for container-0 specification.
- NM replays with its own specification.
- Select and register the NM, create AppMaster for execution.
- Pull shared information and creates required mapper ids.
3.Task Assignment Phase
One of the advantages of Hadoop framework is that the data splits are distributed across the network in multiple data nodes .Thus phase three deals with deploying the mapper task in data node which contains corresponding input splits(see figure 5). Thus the burden of processing in one node is distributed among multiple nodes. Application Master uses the data locality concept. It contacts RM for negotiating resources and submit the data node information which satisfy the data locality criteria and keeps the informations. AM initiate YARN child creation on each specified data node with the same application id as their task id and submit the mapper id to be executed and it also create a temporary local directory in the specified data node. Thus the phase three for task assignment comes to an end.
4. Task Execution Phase
At this point the control is transferred to the particular data nodes which possess the YARN child. It then contact the shared directory on RM to get the related information and copy the files from the shared directory of RM to the locally created temporary directory ie the client.jar and job.xml etc.. This is the main theme of anatomy of mapreduce in hadoop which is pushing the process to data, thus by making data locality possible.
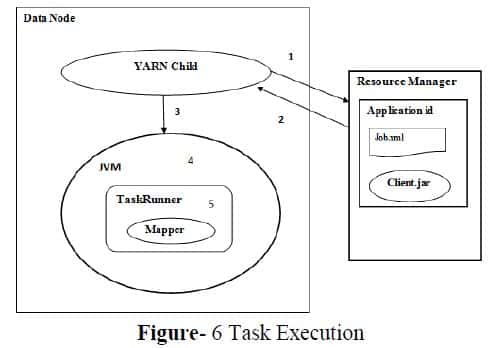
It then sets the class path to the temporary directory because client.jar should be visible to the JVM which is going to be created by the YARN child. For executing the mapper function the JVM is created and execute a MR related framework called TaskRunner which is a java class object executing on the top of locally created directory .TaskRunner will identify which class should run over JVM ie. The Mapper class in client.jar.It then starts executing the Mapper program. The workflow is explained as(see figure-6):-
- Request the shared informations.
- RM transfers the requested files.
- YARN child creates JVM for execution.
- Create TaskRunner to run mapper locally.
- Execute the Mapper program.
5. Progress Update
Once the execution started in distributed data nodes the progress have to be send to the respective initiative modules. Mapper and Reducer JVM execution environment sends progress report to the corresponding AM periodically (every 1second).AM accumulate progress from all MR tasks and communicate to client only if a change in progress happen for every 3 seconds. In reverse client also sends the request of completion in every 5 seconds. Once all the tasks are completed AM cleanup the temporary directory and send the response to the client with the results. Mappers and reducers intermediate output is deleted only when all the tasks got the completion response, otherwise if a reducer fails it still needs the output from the mapper programs.
6. Failue Recovery
Hadoop provides a facility to store the trace of the user and system operation by using FSImage and Edit.logs in the Namenode.The Secondary Namenode checkpoint backup mechanism provides a hard backup technique for hadoop in case if the Namenode goes down.All the informations regarding the executions are saved and if at any point of time the server goes down system calls the log files and restart the execution.Thus the failure handiling is done by the assistance of the framework itself .
Hadoop provides flexible architecture which enables industrialist and even starters to learn and analyse social changes. This is achieved by the highly efficient, fault tolerant framework called MapReduce. This paper is a detailed study of how anatomy of mapreduce job run in Hadoop and MR jobs are executed in the hadoop cluster and how the distributed parallel processing is achieved by pushing process to data in the framework.
How Job runs on MapReduce
Anatomy of a mapreduce job run can be used to work with a solitary method call: submit() on a Job object (you can likewise call waitForCompletion(), which presents the activity on the off chance that it hasn’t been submitted effectively, at that point sits tight for it to finish).
Let’s understand the components –
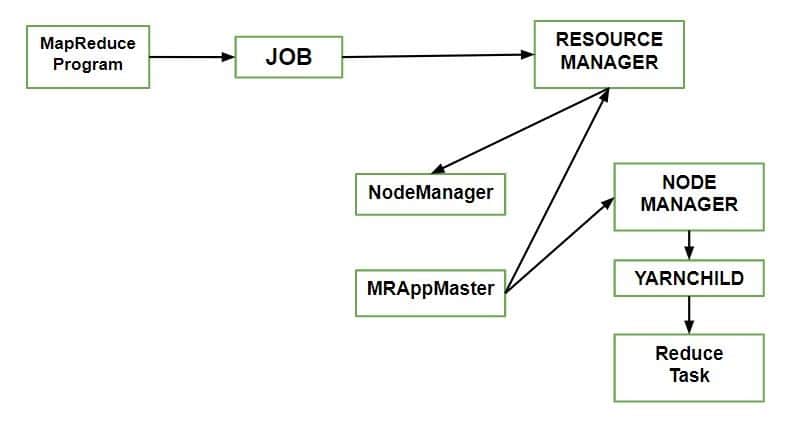
- Client: Submitting the MapReduce job.
- Yarn node manager: In a cluster, it monitors and launches the compute containers on machines.
- Yarn resource manager: Handles the allocation of computing resources coordination on the cluster.
- MapReduce application master Facilitates the tasks running the MapReduce work.
- Distributed Filesystem: Shares job files with other entities.
To create an internal JobSubmitter instance, use the submit() which further calls submitJobInternal() on it. Having submitted the job, waitForCompletion() polls the job’s progress after submitting the job once per second. If the reports have changed since the last report, it further reports the progress to the console. The job counters are displayed when the job completes successfully. Else the error (that caused the job to fail) is logged to the console.
How to submit Job?
Processes implemented by JobSubmitter for submitting the Job :
- The resource manager asks for a new application ID that is used for MapReduce Job ID.
- Output specification of the job is checked. For e.g. an error is thrown to the MapReduce program or the job is not submitted or the output directory already exists or it has not been specified.
- If the splits cannot be computed, it computes the input splits for the job. This can be due to the job is not submitted and an error is thrown to the MapReduce anatomy program.
- Resources needed to run the job are copied – it includes the job JAR file, and the computed input splits, to the shared filesystem in a directory named after the job ID and the configuration file.
- It copies job JAR with a high replication factor, which is controlled by mapreduce.client.submit.file.replication property. AS there are a number of copies across the cluster for the node managers to access.
- By calling submitApplication(), submits the job to the resource manager.
MapReduce Scheduling Challenges
Hundreds of jobs (small/medium/large) may be present on a Hadoop cluster for processing at any given time. How the map and reduce tasks of these jobs are scheduled has an impact on the completion time and consequently on the QoS requirements of these jobs. Hadoop uses a FIFO scheduler out of the box. Subsequently, two more schedulers have been developed. Firstly, Facebook developed the Fair Scheduler which is meant to give fast response time for small jobs and reasonable finish time for production jobs. Secondly, Capacity Scheduler was developed by Yahoo and this scheduler has named queues in which jobs are submitted. Queues are allocated a fraction of the total computing resource and jobs have priorities. It is evident that no single scheduling algorithm and policy is appropriate for all kinds of job mixes. A mix or combination of scheduling algorithms may actually be better depending on the workload characteristics
Essentially, Hadoop is a multi-tasking software product that can process multiple data-sets for multiple jobs for many users at the same time. This means that Hadoop is also concerned with scheduling jobs in a way that makes optimum usage of the resources available on the compute cluster. Unfortunately, Hadoop started off not doing a good job of scheduling in an efficient fashion and even today its scheduling algorithms and schedulers are not all that sophisticated.
At the inception of Hadoop, five or so years ago, the original scheduler was a first-in first-out (FIFO) scheduler woven into Hadoop’s JobTracker. Even though it was simple, the implementation was inflexible and could not be tailored. After all, not all jobs have the same priority and a higher priority job is not supposed to languish behind a low priority long running batch job. Around 2008, Hadoop introduced a pluggable scheduler interface which was independent of the JobTracker. The goal was to develop new schedulers which would help optimize scheduling based on particular job characteristics. Another advantage of this pluggable scheduler architecture is that now greater experimentation is possible and specialized schedulers are possible to cater to an ever increasing types of Hadoop MapReduce applications.
Before it can choose a task for the TaskTracker, the JobTracker must choose a job to select the task from. Having chosen a job, the JobTracker now chooses a task for the job. TaskTrackers have a fixed number of slots for map tasks and for reduce tasks: for example, a TaskTracker may be able to run two map tasks and two reduce tasks simultaneously. The default scheduler fills empty map task slots before reduce task slots, so if the TaskTracker has at least one empty map task slot, the JobTracker will select a map task; otherwise, it will select a reduce task.
Based on published research [31, 3], it is very evident that a single scheduler is not adequate to obtain the best possible QoS out of a Hadoop MapReduce cluster subject to a varying workload. Also, we have seen that almost none of the schedulers consider the contention placed on the nodes due to the running of multiple tasks.
MapReduce Performance Challenges
Hundreds of thousands of jobs of varying demands on CPU, I/O and network are executed on Hadoop clusters consisting of several hundred nodes. Tasks are scheduled on machines, in many cases with 16 or more cores each. Short jobs have a different completion time requirement than long jobs and similarly production level high priority jobs have a different quality of service requirement compared to adhoc query type jobs. Predicting the completion time of Hadoop MapReduce jobs is an important research topic since for large enterprises, correctly forecasting the completion time and an efficient scheduling of Hadoop jobs directly affects the bottom line. A plethora of work is going on in the field of Hadoop MapReduce performance. We briefly talk about a few prominent recent ones which are most relevant to this paper. In his 2011 technical report [16], Herodotou describes in detail a set of mathematical performance models for describing the execution of a MapReduce job on Hadoop. The models can be used to estimate the performance of MapReduce jobs as well as to find the optimal configuration settings to use when running the jobs.
A set of 100 or so equations calculate the total cost of a MapReduce job based on different categories of parameters – Hadoop parameters, job profile statistics and a set of parameters that define the I/O, CPU, and network cost of a job execution. In a 2010 paper, Kavulya et al. analysed ten months worth of Yahoo MapReduce logs and used an instance-based learning technique that exploits temporal locality to predict job completion times from historical data. Though the thrust of the paper is essentially analyzing the log traces of Yahoo, this paper extends the instance based (nearest-neighbor) learning approaches. The algorithm consists of first using a distance-based approach to find a set of similar jobs in the recent past, and then generating regression models that predict the completion time of the incoming job from the Hadoop-specific input parameters listed in the set of similar jobs. In a 2010 paper , Verma et al. design a performance model that for a given job (with a known profile) and its SLO (soft deadline), estimates the amount of resources required for job completion within the deadline. They also implement a Service Level Objective based scheduler that determines job ordering and the amount of resources to allocate for meeting the job deadlines.
In the authors describe an analytic model they built to predict a MapReduce job’s map phase completion time. The authors take into account the effect of contention at the compute nodes of a cluster and use a closed Queuing Network model [22] to estimate the completion time of a job’s map phase based on the number of map tasks, the number of compute nodes, the number of slots on each node, and the total number of map slots available on the cluster.
FAQS:
How to run mapreduce job in hadoop?
How Mapreduce works in Hadoop?
Originally published February 13, 2014 5:23 am, updated on Sep 22, 2022 for relevance and comprehensiveness.
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...