Hadoop 2.0 and YARN Architecture
What is Hadoop 2.0 & YARN?
First off, a big kudos to Hortonworks for the great webinar by Arun C. Murthy ( who by the way was one of the primary people in building/releasing YARN) in which this post is based on. I really recommend watching it here.
The simplest way to understand the difference between Hadoop 1.x and Hadoop 2.x is that the architecture went from being a single use system that only handled Batch jobs to a multi-purpose system that could not only run the batch jobs that Hadoop 1.x did but also more interactive, online, streaming jobs as well. Hadoop went from using only MapReduce for not only its cluster management but also data processing. There was a lot of issues that this brought up including scalability limitations, availability, resource utilization, and more. What the architects and developers of Hadoop 2.0 did essentially was separate the cluster resource management work from MapReduce and built YARN to do it more efficiently and effectively.
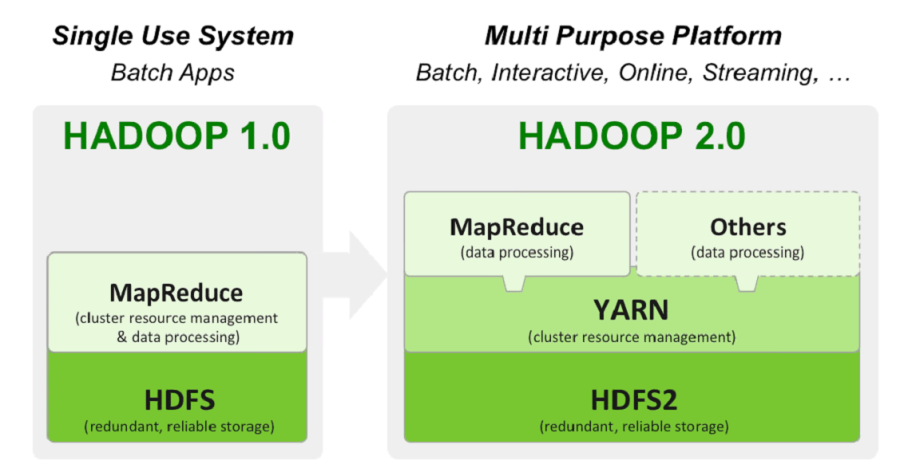 YARN with the updates of HDFS2 allows for users to interact with the data in multiple ways not just by running batch jobs. With tools like Tez, Storm, Spark, and others you can now go straight to the data and have access to all the data in one place. Before one would have to run a batch job to get a data set then work with that data in another space. A couple of really key benefits of YARN are around the ability to scale more than the previous limit (~4k nodes), ability for other tools besides just MapReduce to interact with HDFS and the cluster, better utilization of the clusters resources, and one of the best that I really like is to be able to work with Hadoop and not have to be pinned down to using Java only. I can now use Python and that makes me happy 🙂
YARN with the updates of HDFS2 allows for users to interact with the data in multiple ways not just by running batch jobs. With tools like Tez, Storm, Spark, and others you can now go straight to the data and have access to all the data in one place. Before one would have to run a batch job to get a data set then work with that data in another space. A couple of really key benefits of YARN are around the ability to scale more than the previous limit (~4k nodes), ability for other tools besides just MapReduce to interact with HDFS and the cluster, better utilization of the clusters resources, and one of the best that I really like is to be able to work with Hadoop and not have to be pinned down to using Java only. I can now use Python and that makes me happy 🙂
There are obviously some differences that have come about from Hadoop 2.0 and one is around the concept of jobs. In Hadoop 1.0 they were called “jobs” and everything that was submitted to cluster for processing was a MapReduce Job. Now with the ability to use not only MapReduce but also the others tools like Storm and Spark a job now is referred to as an “Application”. Another concept is around the idea of a “Container”. Before with 1.0 you had fixed map & fixed reduce slots which could lead to resource contraints however with YARN you now have these containers that are basically a unit of allocation. The big payoff with containers is an increased resource utilization.
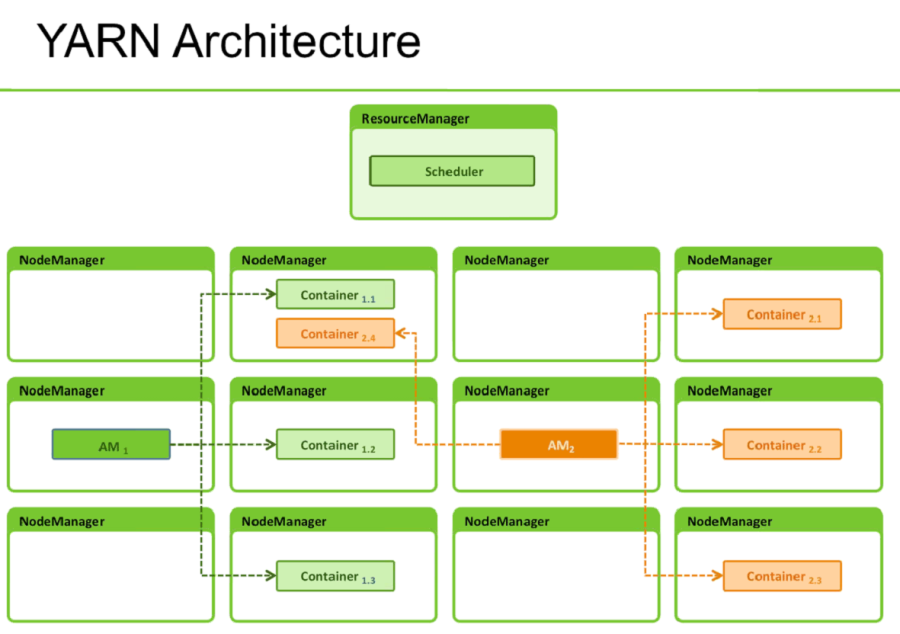
YARN Architecture
YARN is made up of 3 main pieces:
- Resource Manager
- Node Manager
- Application Master
 Resource Manager
Resource Manager
ResourceManager (RM) is the master that arbitrates all the available cluster resources and thus helps manage the distributed applications running on the YARN system. It works together with the per-node NodeManagers (NMs) and the per-application ApplicationMasters (AMs).
- NodeManagers take instructions from the ResourceManager and manage resources available on a single node.
- ApplicationMasters are responsible for negotiating resources with the ResourceManager and for working with the NodeManagers to start the containers.
Node Manager
The NodeManager (NM) is YARN’s per-node agent, and takes care of the individual compute nodes in a Hadoop cluster. This includes keeping up-to date with the ResourceManager (RM), overseeing containers’ life-cycle management; monitoring resource usage (memory, CPU) of individual containers, tracking node-health, log’s management and auxiliary services which may be exploited by different YARN applications.
Application Master
The ApplicationMaster is, in effect, an instance of a framework-specific library and is responsible for negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the containers and their resource consumption. It has the responsibility of negotiating appropriate resource containers from the ResourceManager, tracking their status and monitoring progress.
I hope you enjoyed this post. Stay tuned for another post I am working on around “Implementing Applications with YARN” which will help you in actually utilizing Hadoop and YARN. Source
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...