Facebook HydraBase adds reliability to Hadoop’s HBase
 Facebook’s becoming almost as notable for its adventures with open source projects as it is for its social network of more than 1 billion users. The company’s latest experiment: revising one of Hadoop’s key components to make it more reliable in data centers.
Facebook’s becoming almost as notable for its adventures with open source projects as it is for its social network of more than 1 billion users. The company’s latest experiment: revising one of Hadoop’s key components to make it more reliable in data centers.
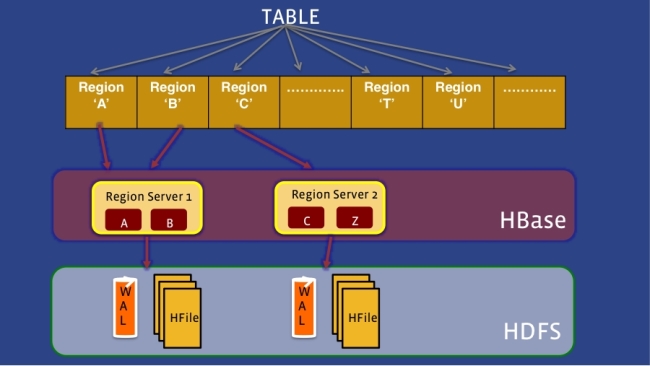
Apache HBase, a project spun off from Google’s Bigtable, is used in Hadoop to deploy large tables of data, in the billions of rows and millions of columns range, across multiple machines. Facebook has been using HBase, with a little tinkering of its own, to host the revamped version of its Messages feature since 2010. Over time, Facebook’s engineers found that HBase was a good fit for a lot of other tasks, such as search indexing or streaming data analysis, and expanded its use.
Unfortunately, Facebook’s engineers ran into a problem with the way HBase held up under failures. The existing way HBase replicated between clusters was too slow for Facebook, since a failover could take minutes to kick in. They reworked HBase to have each failover region hosted by multiple servers, instead of just one, so that failovers could be completed more quickly. What’s more, those servers could be in different racks or even different data centers.
“Another way of thinking about HydraBase,” says Facebook in its blog on HydraBase, “is we’ve effectively decoupled the logical and physical replication. … With HydraBase, we have the potential to increase the reliability of HBase from 99.99% availability to 99.999% if we deploy HydraBase in a cross-data center configuration as shown above. This would translate to no more than five minutes of downtime in a year.”
Appealing as this sounds for Facebook’s users and for Facebook internally, a bigger test of the effectiveness of the changes to HydraBase will lie in how well they perform outside of Facebook. It isn’t clear yet from Facebook’s post if HydraBase will be open-sourced and released outside of Facebook’s labs, or whether the changes are intended to be applied to generic deployments of HBase or Hadoop.
It’s likely that any release would not constitute a formal contribution to HBase’s own code — not just because of what HydraBase is, but because of how Facebook has approached open source projects in the past. When Facebook released the Hack language, a variant of PHP, it was made into its own distinct project rather than as changes to PHP itself. The sheer magnitude of the changes likely made that unavoidable, though.
Right now Facebook states it is testing HydraBase and plans to roll it out across its production clusters in phases. Any release of the code will only come after that process is complete. Source
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...