What Can GPFS on Hadoop Do For You?
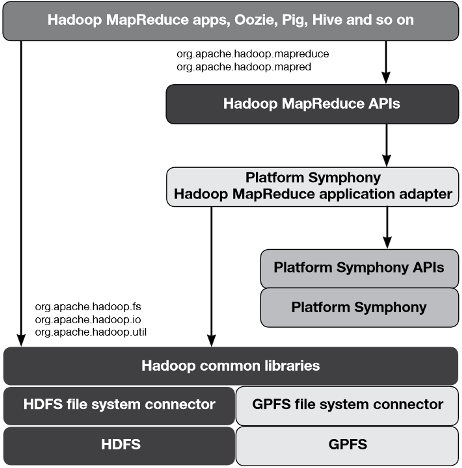 The Hadoop Distributed File System (HDFS) is considered a core component of Hadoop, but it’s not an essential one. Lately, IBM has been talking up the benefits of hooking Hadoop up to the General Parallel File System (GPFS). IBM has done the work of integrating GPFS with Hadoop. The big question is, What can GPFS on Hadoop do for you?
The Hadoop Distributed File System (HDFS) is considered a core component of Hadoop, but it’s not an essential one. Lately, IBM has been talking up the benefits of hooking Hadoop up to the General Parallel File System (GPFS). IBM has done the work of integrating GPFS with Hadoop. The big question is, What can GPFS on Hadoop do for you?
IBM developed GPFS in 1998 as a SAN file system for use in HPC applications and IBM’s biggest supercomputers, such as Blue Gene, ASCI Purple, Watson, Sequoia, and MIRA. In 2009, IBM hooked GPFS to Hadoop, and today IBM is running GPFS, which scales into the petabyte range and has more advanced data management capabilities than HDFS, on InfoSphere BigInsights, its collection of Hadoop-related offerings, as well as Platform Symphony.
GPFS was originally developed as a SAN file system. That would normally prevent it from being used in Hadoop and the direct-attach disks that make up a cluster. This is where an IBM GPFS feature called File Placement Optimization (FPO) comes into play.
Phil Horwitz, a senior engineer at IBM’s Systems Optimization Competency Center, recently discussed how IBM is using GPFS with BigInsights and System x servers, and in particular how FPO has is helping GPFS to make inroads in a Hadoop cluster. (IBM has since sold off the System x business to Lenovo, which IBM now must work closely with for GPFS-based solutions, but the points are still valid).
According to Horwitz, FPO essentially emulates a key component of HDFS: moving the application workload to the data. “Basically, it moves the job to the data as opposed to moving data to the job,” he says in the interview. “Say I have 20 servers in a rack and three racks. GPFS FPO knows a copy of the data I need is located on the 60th server and it can send the job right to that server. This reduces network traffic since GPFS- FPO does not need to move the data. It also improves performance and efficiency.”
Last month, IBM published an in-depth technical white paper titled “Deploying a Big Data Solution Using IBM GPFS-FPO” that explains how to roll out GPFS on Hadoop. It also explains some of the benefits users will see from using the technology. For starters, GPFS is POSIX compliant, which enables any other applications running atop the Hadoop cluster to access data stored in the file system in a straightforward manner. With HDFS, only Hadoop applications can access the data, and they must go through the Java-based HDFS API.
The flexibility to access GPFS-resident data from Hadoop and non-Hadoop applications frees users to build more flexible big data workflows. For example, a customer may analyze a piece of data with SAS. As part of that workflow, they may use a series of ETL steps to manipulate data. Those ETL processes may be best executed by a MapReduce program. Trying to build this workflow on HDFS would require additional steps, as well as moving data in and out of HDFS. Using GPFS simplifies the architecture and minimizes the data movement, IBM says. Read more
Related Posts

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...