Actian Brings Graph Analysis To Big Data
 Actian announced that it’s adding a graph-analysis engine to its big data portfolio, which already includes a SQL-on-Hadoop offering as well as several relational databases and data-integration software.
Actian announced that it’s adding a graph-analysis engine to its big data portfolio, which already includes a SQL-on-Hadoop offering as well as several relational databases and data-integration software.
Graph analysis is applied to uncover networked relationships among people, places, things, and entities. It’s at the core of Facebook’s ability to uncover relationships, and in business it’s used to uncover customer relationships in retail and telecommunications; governance and compliance relationships and risks in financial services industries; and claim and readmission risk analysis in healthcare.
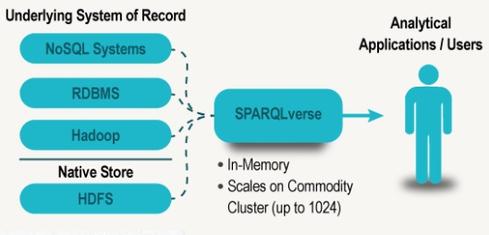
Actian’s new graph analysis option is SPARQLverse, an in-memory engine that employs the World Wide Web Consortium’s (W3C) SPARQL Protocol and RDF Query Language standard. SPARQLverse was developed by SPARQL City, a separate software engineering company that Actian has invested in but that has limited sales and marketing capacity of its own. Actian will act as a SPARQLverse reseller.
There’s no shortage of popular products that have implemented SPARQL, including popular databases from IBM and Oracle and graph-analysis-specific products including Neo4J, Cray’s Urika-GD, and Sqrrl (built on Apache Accumulo). Other popular or up-and-coming graph-analysis options that don’t use SPARQL include Apache Spark GraphX, Apache Giraph, the Titan distributed graph database, and Teradata’s SQL-GR engine.
So why use SPARQLverse when other options offer either wide adoption and popularity or, in the case of Apache Spark and Teradata, multiple analysis options on a single analytic platform?
Products that don’t use SPARQL “have no standard, declarative, SQL-like language,” according to Barry Zane, SPARQL City’s CEO, while other products “can’t match SPARQLverse in-memory, parallel-processing performance,” he says.
Zane points to SPARQL City benchmark tests that show that its product runs 10 times faster on 100 times the data volume handled by “other graph solutions.” The list of other products includes less-well-known products including the Java engine ARQ on top of open source Jena, the Redland RDF Processor, Java-based Sesame, and OpenLink Virtuoso.
SPARQLverse can run on top of Hadoop and also query Hadoop as well as relational and NoSQL sources, but it’s a separate engine from the Actian Analytics Platform Hadoop SQL Edition. Actian describes its collection of products as an analytics platform, but it has yet to integrate separate products in terms of administration or analysis — a Spark vision and strength that companies including Teradata have tried to match.
SPARQLverse can also run as a stand-alone, distributed cluster on HDFS. SPARQL City is working with a big investment bank as a beta customer, according to Zane, but he said he could not disclose the name of the company.
SPARQL City is developing applications including insider-trading and derivatives reporting. The insider-trading app looks across trading data and geospatial information to uncover non-obvious connections among traders. The derivatives-reporting app looks at product and geospatial data to accurately identify the source of derivatives products worldwide.
Actian says it’s considering an even wider scope of graph-analysis applications, including fraud detection, DNA research, customer-influence analysis, and Internet-of-Things log analysis. source
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...