5 Reasons You Should Consider Implementing DataOps
 Since the appearance of the term, in 2015, DataOps is getting great interest and is well received among data scientists, analysts and data managers and those working with data usage and data value. Driving data value by applying Agile methodology to the data processing pipeline, is the main goal of the DataOps approach.
Since the appearance of the term, in 2015, DataOps is getting great interest and is well received among data scientists, analysts and data managers and those working with data usage and data value. Driving data value by applying Agile methodology to the data processing pipeline, is the main goal of the DataOps approach.
In this article, I’ll explain what exactly is DataOps, the differences between DevOps and DataOps and the top reasons to implement a DataOps model now. Read on to find out more.
What Is DataOps?
DataOps is the process of combine synergistically DevOps practices with data engineering and data science insights and expertise. It involves having data and internal systems ready for testing according to the requirements of a DevOps environment.
While DevOps focuses on improving the software development pipeline, DataOps focus its efforts in optimizing data analytics capabilities and data orchestration. It works on the assumption that data needs to be managed and secured regardless of where it lives, applying agile and collaborative techniques to data delivery.
Therefore, the model streamlines disparate activities in the data process pipeline, such as data sourcing, preparation, cleansing, loading, testing, deployment, analysis and science with the goal of accelerating data delivery. Ultimately it is clear that there are a number of benefits of investing in DataOps practices within your business.
By speeding the delivery time, the model helps to increase business value. As DevOps, emphasizes operational transparency, by considering data as an asset and a rigorous protocol for delivering and protecting the data.
A data science team nowadays needs to process huge numbers of data, coming from disparate sources with a delivery rate that has to keep up with the DevOps model. More often than not there is no time for once-a-quarter releases, you need to catch up and release every week. Therefore, you need to apply the DevOps principles to data processing. It addresses the issues of speed, quality and security. Since data must be protected along the entire pipeline, it seems logical to apply DevOps security principles including automating processes.
Security practices and controls need to be integrated across the DataOps process from sourcing to delivery.
Common use cases for DataOps include the sharing of operational databases, and companies moving data to the cloud.
How Is DataOps Different From DevOps And DevSecOps?
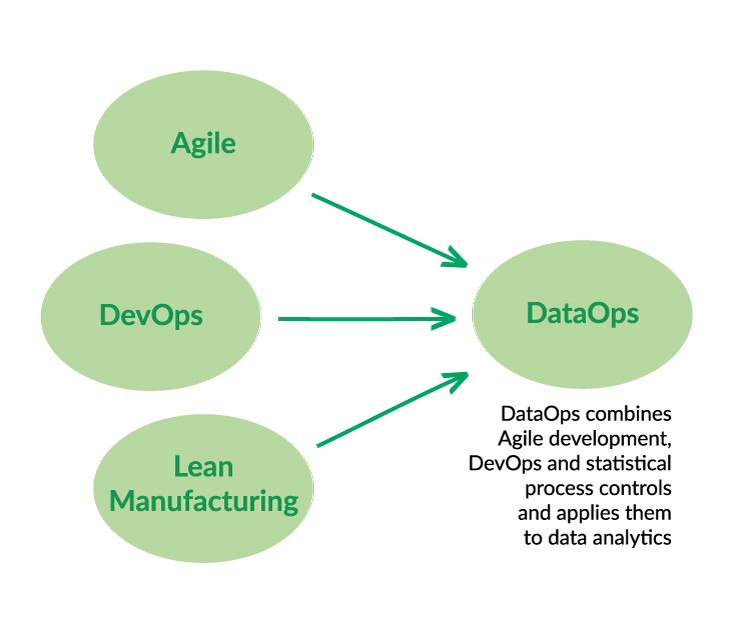 DataOps differs from DevOps firstly, because while DevOps is focused on improving the software development process, DataOps aims to simplify the work of data scientists. Both professionals have very distinct approaches to work. Developers embrace technology, interesting themselves with the details of code creation, integration and deployment, and find complexity a welcomed challenge.
DataOps differs from DevOps firstly, because while DevOps is focused on improving the software development process, DataOps aims to simplify the work of data scientists. Both professionals have very distinct approaches to work. Developers embrace technology, interesting themselves with the details of code creation, integration and deployment, and find complexity a welcomed challenge.
On the other hand, data science thrives in simplification, being happy using one or two tools, therefore DataOps works around the need of data professionals for a simplified process. Let’s review the differences between DevOps and DataOps according to their processes:
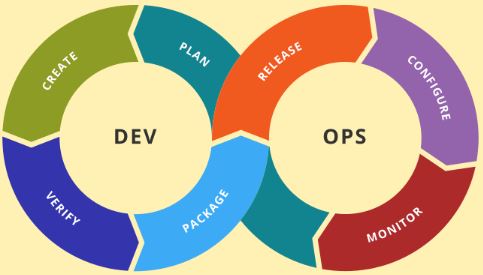 The DevOps lifecycle is usually illustrated using a diagram in the shape of a loop, where the process iterates indefinitely. DataOps shares this iteration in its process but instead of a loop, the process consists of two intersecting pipelines, the data factory and the data update.
The DevOps lifecycle is usually illustrated using a diagram in the shape of a loop, where the process iterates indefinitely. DataOps shares this iteration in its process but instead of a loop, the process consists of two intersecting pipelines, the data factory and the data update.
The data factory or Value Pipeline involves taking raw data from disparate sources and producing analytic insights creating value for the organization. A DataOps model automates orchestration, monitoring the quality of the data. Intersecting that is the Innovation Pipeline involves introducing new ideas into the Value Pipeline.
A good implementation of the DataOps model should integrate DevSecOps practices, as the goal is not only to speed the delivery of data, but to protect it along the pipeline. Therefore, implementing DevOps security controls is imperative to deliver secure data.
5 Reasons To Implement DataOps
The key benefits you can leverage when adopting a DataOps solution can be resumed in the following:
- Enhances data analytics—DataOps combines multiple analytic methods helping data scientist to gather, process, analyze and deliver data to the final destination. This allows to keep an eye on the data across the process, improving the analysis.
- Facilitates the application of data to solve problems—due to the rapid growing rate of the data, sometimes data scientists lack the time to catch up and apply the data effectively. A more agile process, aided by the automating of several tasks, allows for an easier application of the data insights.
- Improves the reaction to market changes—since DataOps changes the whole workflow process in the company, the synergy of all departments improves the response rate, resulting in better adapting to sudden changes in the market.
- Enables to handle big data—this makes it easier to adopt Artificial Intelligence and Machine Learning solutions, which enhances data orchestration. Implementing a DataOps strategy enables the company to handle big data efficiently, extracting valuable information and eventually gaining a competitive advantage.
- Enables continuous strategic data management practices—implementing a DataOps solution involves automating all possible processes, improving data integrity and preventing human errors. This in turn, increases the security of the data going through the pipelines.
Conclusion
Incorporating a DataOps model to your organization increases the operability by integrating the data into the Agile methodology of DevOps and DevSecOps. That results into a seamless model going across your organization departments, including the management of the data, the production and the security.
DataOps allows users to have full interoperability with data sources, streamlining effectively the data management and analytics. At the end of the day, DataOps helps you improve your product delivery and deployment with secure and up-to-date data value.
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...