5 technologies that will help big data cross the chasm
 We’re on the cusp of a real turning point for big data. Its applications are becoming clearer, its tools are getting easier and its architectures are maturing in a hurry. It’s no longer just about log files, clickstreams and tweets. It’s not just about Hadoop and what’s possible (or not) with MapReduce.
We’re on the cusp of a real turning point for big data. Its applications are becoming clearer, its tools are getting easier and its architectures are maturing in a hurry. It’s no longer just about log files, clickstreams and tweets. It’s not just about Hadoop and what’s possible (or not) with MapReduce.
With each passing day, big data is becoming more about creativity — if someone can think of an application, they can probably build it. That makes the concept of big data a lot more tangible and a lot more useful to a lot more companies, and it makes the market for big data a lot more lucrative.
Here are five technologies helping spur a shift in thinking from “Why would I want to use some technology that Yahoo built? And how?” to “We have problem that needs solving. Let’s find the right tool to solve it.”
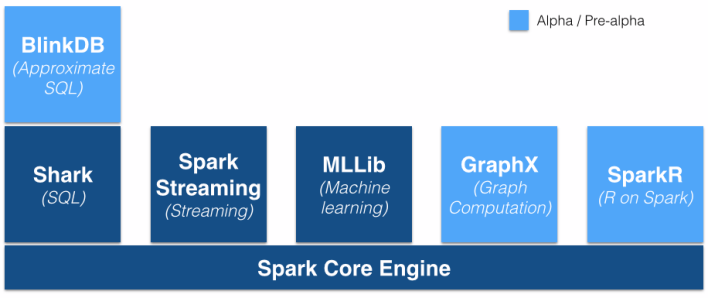
Apache Spark
When it comes to open source big data projects, they don’t get much hotter than Apache Spark. The data-processing framework is garnering a lot of users and a lot of supporters — including from Hadoop vendors MapR and Cloudera — because it promises to be almost everything for Hadoop deployments (arguably the foundation of most enterprise big data environments) that MapReduce wasn’t. It’s fast, it’s easy to program and it’s flexible.
Right now, Spark is getting a lot of attention as an engine for machine-learning workloads — for example, Cloudera Oryx and even Apache Mahout are porting their code bases to Spark — as well as for interactive queries and data analysis. As the project’s community grows, the list of target workloads should expand, as well.
Cloud computing
This might seem obvious — we’ve been talking about the convergence of cloud computing and big data for years — but cloud computing offerings have advanced significantly in the just the past year. There are bigger, faster and ever-cheaper raw compute options, many offering high memory capacity, solid-state drives or even GPUs. All of this makes it much easier, and much more economically feasible, to run myriad types of data-processing workloads in the cloud.
The market for managed Hadoop and database services continues to grow, as well as the market for analytics services. They’re quickly adding new capabilities and, as the technologies underpinning them advance, they’re becoming faster and more scalable.
Sensors
A lot of talk about sensors focuses on the volume and speed at which they generate data, but what’s often ignored is the strategic decisions that go into choosing the right sensors to gather the right data. If there’s are real-world measurements that need to be taken, or events that need to be logged, there’s probably a fairly inexpensive sensor available to do the job. Sensors are integral to smarter cars, of course, but also to everything from agriculture to hospital sanitation.
And if there’s not a usable sensor commercially available, it’s not inconceivable to build one from scratch. A team of university researchers, for example, built a cheap sensor to measures the wing speed of insects using a cheap laser pointer and digital recorder. It helped them capture more, better data than previous researchers, resulting in a significantly more-accurate model for classifying bugs.
Artificial intelligence
Thanks to the proliferation of data in the form of photos, videos, speech and text, there’s now an incredible amount of effort going into building algorithms and systems that can help computers understand those inputs. From a big data perspective, the interesting thing about these approaches — whether they’re called deep learning, cognitive computing or some other flavor of artificial intelligence — is that they’re not yet really about analytics in the same way so many other big data projects are.
AI researchers aren’t so concerned — yet — with uncovering trends or finding the needle in the haystack as they are with automating tasks that humans can already do. The big difference, of course, is that, done right, the systems can perform tasks such as object or facial recognition, or text analysis, much faster and at a much greater scale than humans can. As they get more accurate and require less training, these systems could power everything from intelligent ad platforms to much smarter self-driving cars.
Quantum computing
Commercial quantum computing is still a way off, but we can already see what might be possible when it arrives. According to D-Wave Systems, the company that has sold prototype versions of its quantum computer to Google, NASA and Lockheed Martin, it’s particularly good at advanced machine learning tasks and difficult optimization problems. Google is testing out computer vision algorithms that could eventually run on smartphones; Lockheed is trying to improve software validation for flight systems. Read more
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...