Impala and SQL on Hadoop
 The origins of Impala can be found in F1 – The Fault-Tolerant Distributed RDBMS Supporting Google’s Ad Business.
The origins of Impala can be found in F1 – The Fault-Tolerant Distributed RDBMS Supporting Google’s Ad Business.
One of many differences between MapReduce and Impala is in Impala the intermediate data moves from process to process directly instead of storing it on HDFS for processes to get at the data needed for processing. This provides a HUGE performance advantage and doing so while consuming few cluster resources. Less hardware to-do more!
There are many advantages to this approach over alternative approaches for querying Hadoop data, including::
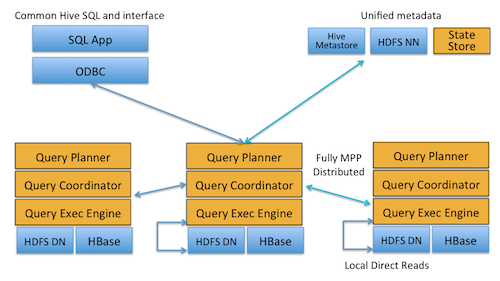
- Thanks to local processing on data nodes, network bottlenecks are avoided.
- A single, open, and unified metadata store can be utilized.
- Costly data format conversion is unnecessary and thus no overhead is incurred.
- All data is immediately query-able, with no delays for ETL.
- All hardware is utilized for Impala queries as well as for MapReduce.
- Only a single machine pool is needed to scale.
We encourage you to read the documentation for further exploration!
There are still transformation steps required to optimize the queries but Impala can help to-do this for you with Parquet file format. Better compression and optimized runtime performance is realized using the ParquetFormat though many other file types are supported. Read more
Related Posts

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...

7 Top Autonomous AI Pentesting Platforms in 2026
June 10, 2026Autonomous penetration testing is becoming one of the most important changes in ...