4 Easy Steps to Master Apache Hadoop Development
 If you are huge fan of Big Data then you definitely need to know Apache Hadoop development. It will help you flourish your skills and raise your career to the next level.
If you are huge fan of Big Data then you definitely need to know Apache Hadoop development. It will help you flourish your skills and raise your career to the next level.
You must be wondering where does this much storage comes from. Some real facts for you, this will definitely make your eyes pop out!
- Google process nearly 700 PB per month
- Facebook host up to 10 billion photos and that needs 1PB storage
- New York Stock Exchange generates approximately 1TB per day
- LinkedIn and Google+ requires millions of terabytes on daily bases
For this much information you need a server that can easily handle it and Apache Hadoop was able to do that. Apache Hadoop is an open source software framework, created by Doug Cutting that is utilized for the distribution of storage and to process large bulky data usually written in Java. Hadoop can quickly and steadily analyze large amount of data whether it is organized or unorganized. Before you go for understanding Apache Hadoop, firstly you need to install Hadoop on Windows with Eclipse on your PC or laptop. Here are few easy step that would help you in mastering Apache Hadoop development. To get training in Hadoop administration, click here.
1# Core Components
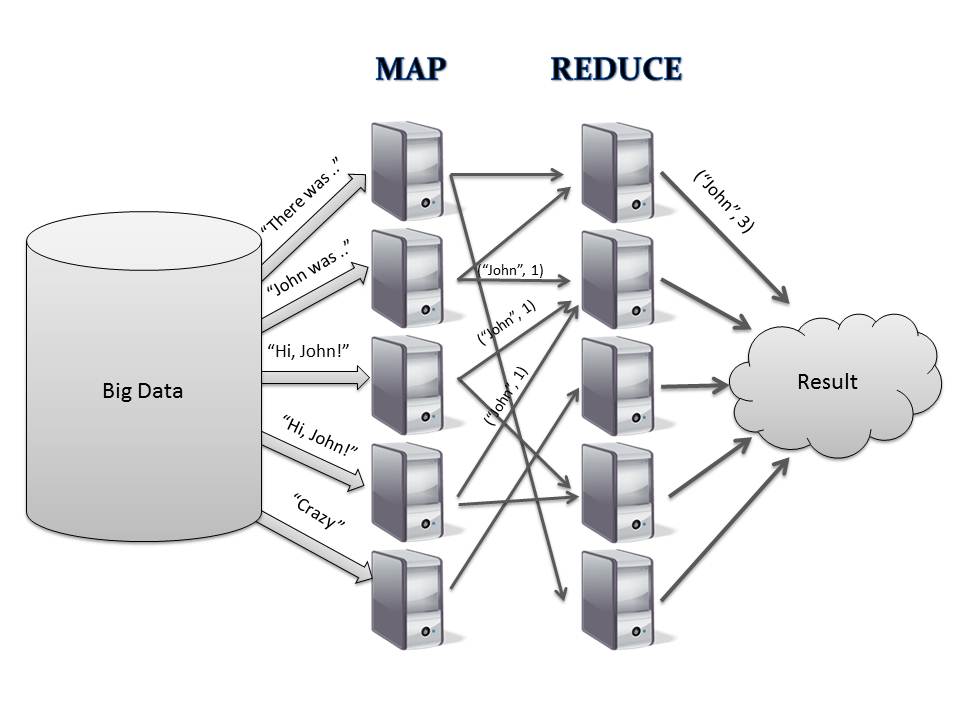 For writing distributed applications you need a parallel programming model known as MapReduce. These applications are devised at Google as it is efficient enough to process a large multi-terabyte data-sets on thousands of nodes of product hardware. MapReduce works on Hadoop.
For writing distributed applications you need a parallel programming model known as MapReduce. These applications are devised at Google as it is efficient enough to process a large multi-terabyte data-sets on thousands of nodes of product hardware. MapReduce works on Hadoop.
Working of MapReduce is simple to understand, a list of records are given, represented in pairs. There are 2 phases in one Map Phase and Reduce Phase. The records are distributed in an unorderly way but each of them are processed separately as independent items. This is the Map phase, in Reduce phase, records having same keys are grouped together and their processing is done in the same computing node. Thus you get the result at the end.
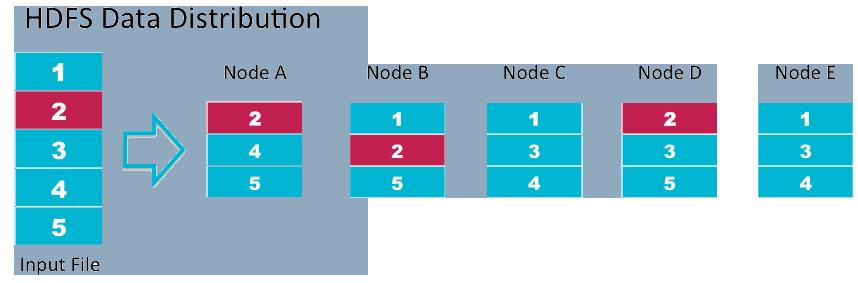 HDFS is a self-healing and fault tolerant distributed file system well designed to turn huge industrial standard servers turned into massive pool of storage. It is based on the Google File System and provides a gigantic amount of data which is distributed across several machines. It provides high band widths all across the cluster that is of machines.
HDFS is a self-healing and fault tolerant distributed file system well designed to turn huge industrial standard servers turned into massive pool of storage. It is based on the Google File System and provides a gigantic amount of data which is distributed across several machines. It provides high band widths all across the cluster that is of machines.
Data in HDFS is replicated across many nodes for better computer performance and data protection. For more information, click here.
2# Two Modules of Apache Hadoop Development
Apart from the two components mentioned above, Hadoop framework comprises of following two modules:
- Hadoop common: These are the Java libraries and utilities required by other Hadoop modules.
- Hadoop YARN: this framework is used for group of resource management and job scheduling.
3# Three Modes of Hadoop Development
- Standalone Mode
On configuring Hadoop on a single machine is known as Standalone Mode. The single machine is called as Ubuntu machine which is the host. It is called standalone as it is quite straightforward and does not require major changes.
- Fully Distributed Mode
In this environment virtual machine are distributed on real-time and quite similar to Pseudo-Distributed Mode.
- Pseudo-Distributed Mode
In this mode, we configure Hadoop on more than one machine, in this one is the master machine and the rest are the slaves.
4# Environment
You need several software installed before using Hadoop, otherwise it won’t work.
- Ubuntu 10.10
- JDK 6 or above
- Hadoop-1.1.2
- Eclipse
All this looks like a lot of work but it’s very flexible and easily scalable. The main issue that may arise is in debugging the code that you have written. It is really a new level of pain in Hadoop. But instead of looking for compilation errors, just track down what might have happened in your cluster which will be different each time you run your app. Thank God! There are some amazing apps that helps in removing the bugs from your code like Cascading.
Interested in Hadoop development? You don’t really need a license or degree to get started although there are institutes that offer big data and hadoop training.
The post is by Andrea Bell, a Freelance writer and a content contributor at zeolearn, which provides angularJS and big data hadoop training.
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...