What Is a Vector Database & Top 8 Vector Databases for AI & ML Projects
Nowadays, more and more businesses use vector databases for their day-to-day processes. With this kind of technology, you can store and access large quantities of data in just about any format, ranging from text to images, videos, and audio content.
Most importantly, by using a vector database, you can establish relationships between two data points. Companies use them to create recommendation engines, improve browsing experience, detect anomalies, and perform data clustering.
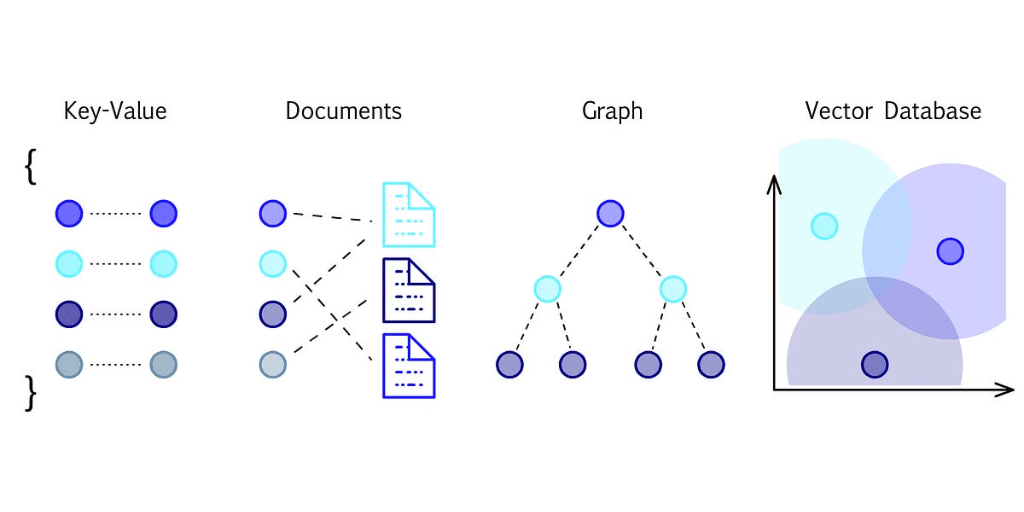
Vector Database Basics
In a normal database, numbers, strings, and other data are represented in columns and rows. In comparison, a vector database relies exclusively on vectors, making the database more optimized and changing its common use cases.
When we use a vector database, all data is stored within a virtual space. The connections between two data points are showcased with vectors, allowing us to determine their differences and similarities. These systems rely on ANN or Approximate Nearest Neighbor search to determine mutual relationships.
With a vector database, you can quickly and accurately retrieve related data points. Given that the database can only provide approximation, we commonly have to sacrifice accuracy for speed. In other words, the slower the query processing the more accurate the results and vice versa.
How Do Vector Databases Work?
Here’s how all this works in practice:
- A vector database creates an index of vectors by relying on specific algorithms such as HNSW, PQ, or LSH. Vectors are placed on a virtual map, which will later allow for faster retrieval
- During the querying process, the databases make a comparison between indexed vectors and indexed query vectors, focusing on the closest neighbors based on their similarities
- Sometimes, the process includes additional post-processing, during which a database might rank neighbors once again by using different parameters
While a vector database is fantastic for establishing similarities between two data points, it doesn’t work that well for complex queries. As such, many companies prefer using a graph database for establishing patterns and analyzing several data sets concurrently.
What Makes Vector Databases Great?
Users index vectors into the database, which allows them to establish relationships between two data points. That way, data practitioners can process embedding models. By relying on database features such as security controls, resource management, fault tolerance, and rapid information retrieval, users can improve their development process.
Vector databases also allow data practitioners to create unique applications and features for their target audiences. For example, you can integrate search and recommendation functions into various programs, thus increasing their usefulness.
Another thing that makes vector databases great is the way they support machine learning processes. These systems can perform natural language processing and deliver on-demand real-time data to users. That way, your software can deliver more relevant results to queries based on the understanding of context.
Main Advantages and Disadvantages
Vector databases can be a perfect solution for developing certain types of software and systems, while they utterly fail in other tasks. Specifically, companies use them to create ML models and process search queries, although these solutions struggle with more complex tasks.
Pros
- Vector databases provide enormous flexibility in terms of content that you can use. They can be implemented in both structured data (numbers, text, and symbols) and unstructured data (various types of files and documents). As such, they can be of great help for various searches and recommendation engines
- This type of technology integrates well with ML models, which puts it at the forefront of the AI revolution. The software can explore billions of vectors and provides a certain level of scaling, although it isn’t as effective as graph databases.
- Although vector databases don’t provide the same type of scaling as some other modern databases, they definitely beat traditional databases in terms of performance. They can handle large quantities of data, which can come in handy in various application
- Another major benefit is improved automation, which stems from using vector databases for machine learning systems. Companies can use these systems for knowledge bases and internal searches, as well as various other solutions that would help them improve user experience
- Companies can use vector databases to execute various similarity searches. This type of database can determine relationships between two data points within a multi-dimensional space, making it ideal for comparative analysis
Cons
- Reduced accuracy is one of the biggest issues when using vector databases. As the number of data increases and queries go beyond similarity searches, it becomes harder for the database to provide relevant results due to its innate limitations
- In many cases, users have to sacrifice speed for accuracy or vice versa. This dynamic can be troublesome for companies looking for quick solutions to their issues
- As the data quantity increases, users will notice a major reduction in data availability and efficiency. Again, this has to do with systems’ innate limitations and inability to process complex data sets
- Unlike some other types of databases, vector databases have high memory and storage requirements. This issue becomes even more noticeable as the quantity of data increases, which will hinder scaling
Top 8 Vector Databases for AI & ML Projects in 2024

The landscape of vector databases (Image Source)
As AI and machine learning (ML) projects continue to evolve, the need for efficient data management and retrieval systems becomes increasingly critical. Vector databases, designed to handle high-dimensional vectors generated by ML models, play a pivotal role in this process. Here, we explore the top eight vector databases for AI and ML projects in 2024, highlighting their unique features and capabilities.
1. Vectara
Vectara is a high-performance vector database designed for large-scale AI and ML applications. It excels in handling high-dimensional vector searches and offers robust support for various machine learning frameworks.
Key Features:
- Real-time vector similarity search
- Scalability to handle large datasets
- Integration with popular ML libraries
- Advanced indexing and retrieval mechanisms
2. Pinecone
Pinecone is a cloud-native vector database that provides a scalable and efficient solution for managing and querying vector embeddings. It is designed to support AI applications with high-dimensional data.
Key Features:
- Fully managed service with automatic scaling
- Real-time updates and queries
- Support for various distance metrics (e.g., cosine, Euclidean)
- Seamless integration with machine learning pipelines
3. SingleStore Database
SingleStore, formerly known as MemSQL, is a hybrid database that combines the capabilities of relational databases with vector search. It is ideal for applications that require both structured data processing and vector similarity search.
Key Features:
- Unified storage for structured and unstructured data
- High-performance vector search
- Real-time analytics and reporting
- Integration with major data science tools
4. Weaviate
Weaviate is an open-source vector search engine that provides a highly flexible and scalable solution for AI and ML projects. It supports various vectorization models and offers rich metadata management.
Key Features:
- Schema-based approach to data management
- Support for multiple vectorization models (e.g., transformers, BERT)
- GraphQL API for querying
- Scalable architecture for large datasets
5. Qdrant
Qdrant is a high-performance vector similarity search engine designed for real-time applications. It is optimized for low-latency queries and can handle large volumes of high-dimensional data efficiently.
Key Features:
- Real-time vector search with low latency
- Advanced indexing techniques
- Support for various distance metrics
- Easy integration with ML workflows
6. Chroma DB
Chroma DB is a vector database specifically designed for handling large-scale vector embeddings generated by deep learning models. It offers robust performance and scalability for AI-driven applications.
Key Features:
- Efficient vector storage and retrieval
- Support for dynamic data updates
- High throughput and low-latency queries
- Integration with deep learning frameworks
7. Zilliz
Zilliz is an open-source vector database built for AI and ML applications. It leverages advanced indexing and search algorithms to provide fast and accurate vector similarity search.
Key Features:
- Scalable architecture for large datasets
- Advanced vector indexing techniques
- Real-time data ingestion and querying
- Integration with popular AI frameworks
8. Milvus
Milvus is an open-source vector database designed to manage and search massive vector embeddings efficiently. It is optimized for high-performance and low-latency operations, making it ideal for AI applications.
Key Features:
- Distributed architecture for scalability
- Support for multiple distance metrics
- Real-time data processing and querying
- Seamless integration with machine learning pipelines
Choosing a Vector Database
Whether or not you’ll have a positive experience with a vector database depends on the product you’re using. Like with any other software, you need to choose a database that fits your particular company needs. Among others, you need to pay attention to integrations, supported data models and scalability.
That being said, these are the main things you should keep in mind when choosing a database:
- Performance
The main thing you need to consider is performance coupled with scalability. You need to see how much data a vector database can process before slowing down and losing accuracy. Specifically, you should analyze throughput and response times, as this will affect your workload requirements.
- Ease of Use
Even if you’re not that great with vector databases, you shouldn’t have too much trouble configuring and setting up a system. You also need to consider how much maintenance a system requires. Good documentation and user-friendly interface can help you get acquainted with the software and start producing better results faster.
- Data Model and Indexing
You should also take into account indexing methods and data model. Consider the indexing mechanisms so you can be certain that similarities searches and retrievals are efficient.
- Integrations
In this day and age, you need software that can be integrated with various other programs. Similarly, your vector database should easily integrate with your existing IT structure, programming languages, and tools. We suggest you analyze SDKs, APIs, and connectors before purchasing a product.
- Support
Even if you’re proficient with a database, you might have a few questions for their support team. Because of that, it’s much better to pick products that have great call centers and knowledge bases you can tap into. It also wouldn’t hurt if a company has active community that can help you out.
Conclusion
Using a vector database can be a real game-changer for your company. These solutions can be used to develop all sorts of software that can be used internally or sold to external entities. By relying on vectors, these databases can establish relationships between numerous data points, which is vital when creating search and recommendation engines. Nowadays, vector databases are commonly used for the development of machine learning solutions, making them an invaluable component for any IT brand.
Related Posts

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...