Selecting the right SQL-on-Hadoop engine to access big data
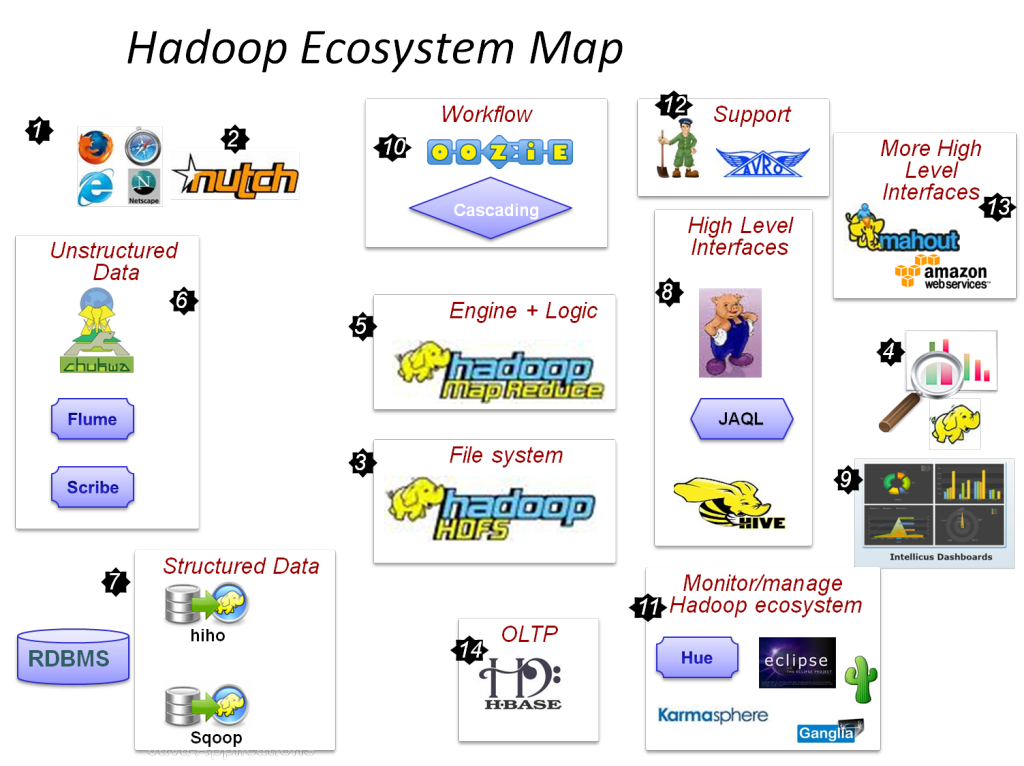 With SQL-on-Hadoop technologies, it’s possible to access big data stored in Hadoop by using the familiar SQL language. Users can plug in almost any reporting or analytical tool to analyze and study the data. Before SQL-on-Hadoop, accessing big data was restricted to the happy few. You had to have in-depth knowledge of technical application programming interfaces, such as the ones for the Hadoop Distributed File System, MapReduce or HBase, to work with the data. Now, thanks to SQL-on-Hadoop, everyone can use his favorite tool. For an organization, that opens up big data to a much larger audience, which can increase the return on its big data investment.
With SQL-on-Hadoop technologies, it’s possible to access big data stored in Hadoop by using the familiar SQL language. Users can plug in almost any reporting or analytical tool to analyze and study the data. Before SQL-on-Hadoop, accessing big data was restricted to the happy few. You had to have in-depth knowledge of technical application programming interfaces, such as the ones for the Hadoop Distributed File System, MapReduce or HBase, to work with the data. Now, thanks to SQL-on-Hadoop, everyone can use his favorite tool. For an organization, that opens up big data to a much larger audience, which can increase the return on its big data investment.
The first SQL-on-Hadoop engine was Apache Hive, but during the last 12 months, many new ones have been released. These include CitusDB, Cloudera Impala, Concurrent Lingual, Hadapt, InfiniDB, JethroData, MammothDB, Apache Drill, MemSQL, Pivotal HawQ, Progress DataDirect, ScleraDB, Simba and Splice Machine.
In addition to these implementations, all the data virtualization servers should be included because they also offer SQL access to Hadoop data. In fact, they are designed to access all kinds of data sources, including Hadoop, and they allow different data sources to be integrated. Examples of data virtualization servers are Cirro Data Hub, Cisco/Composite Information Server, Denodo Platform, Informatica Data Services, Red Hat JBoss Data Virtualization and Stone Bond Enterprise Enabler Virtuoso.
And, of course, there are a few SQL database management systems that support polyglot persistence. This means that they can store data in their own native SQL database or in Hadoop; by doing so, they also offer SQL access to Hadoop data. Examples are EMC/Greenplum UAP, HP Vertica (on MapR), Microsoft PolyBase, Actian ParAccel and Teradata Aster Database (via SQL-H).
SQL equality on Hadoop?
In other words, organizations can choose from a wide range of SQL-on-Hadoop engines. But which one should be selected? Or are they so alike that it doesn’t matter which one is picked?
The answer is that it does matter, because not all of these technologies are created equal. On the outside, they all look the same, but internally they are very different. For example, CitusDB knows where all the data is stored and uses that knowledge to access the data as efficiently as possible. JethroData stores indexes to get direct access to data, and Splice Machine offers a transactional SQL interface.
Selecting the right SQL-on-Hadoop technology requires a detailed study. To get started, you should evaluate the following requirements before selecting one of the available engines.
SQL dialect. The richer the SQL dialect supported, the wider the range of applications that can benefit from it. In addition, the richer the dialect, the more query processing can be pushed to Hadoop and the less the applications and reporting tools have to do.
Joins. Executing joins on big tables fast and efficiently is not always easy, especially if the SQL-on-Hadoop engine has no idea where the data is stored. An inefficient style of join processing can lead to massive amounts of I/O and can cause colossal data transport between nodes. Both can result in really poor performance.
Non-traditional data. Initially, SQL was designed to process highly structured data: Each record in a table has the same set of columns, and each column holds one atomic value. Not all big data in Hadoop has this traditional structure. Hadoop files may contain nested data, variable data (with hierarchical structures), schema-less data and self-describing data. A SQL-on-Hadoop engine must be able to translate all these forms of data to flat relational data, and must be able to optimize queries on these forms of data as well. Read more
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...