Hadoop on OpenStack-Elastic Data Processing (EDP) with Savanna 0.3
Now that version 0.2 of Project Savanna is out, it’s time to start looking at what will be coming up in version 0.3. The goal for this next development phase is to provide elastic data processing (EDP) capabilities, creating a Savanna component that enables data analysis and transformation in an easy and resource-effectively way, running a Hadoop cluster only when it’s needed.
To provide this functionality, Savanna needs you to give it these three things:
The data for processing
A program that specifies how the data will be processed
The location where that program will be executed
These three items define the architecture for the EDP part of Savanna. You can see the high-level architecture in this figure:
As you can see from the image, EDP is made up of the following components:
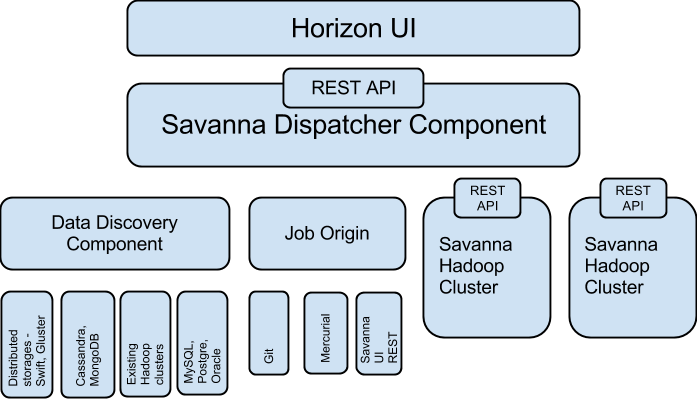
Data discovery component—Enables pulling data from various data sources. Data can be pulled from Swift, GlusterFS, or NoSQL database such as Cassandra or HBase.
Job origin—Supplies a task for data processing and execution on the cluster and allows users to execute several types of job: jar file, Pig and Hive scripts, and Oozie job flows.
Dispatcher component—Responsible for scheduling the job on the new or existing cluster, provisioning a new cluster, resizing cluster and gathering information from clusters about current jobs and utilization.
UI component—Enables integration with the OpenStack Dashboard (Horizon). It’s future intent is to provide instruments for job creation, monitoring, and so on. Hue already provides part of this functionality: submitting jobs (jar file, Hive, Pig, Impala), viewing job status, and outputting.
Data for processing
The data for processing can be stored in various locations and have various representations. Let’s take a look at different uses cases for data locations Savanna is planning to support:
Raw files stored in distributed storage such as Swift, Gluster, Ceph, or an existing Hadoop cluster. The idea of Hadoop was initially born to address this use case, and it still remains a major power when we need to process huge amounts of data quickly, when the order of data processing is not critical, and when we expect to process all of the data, as opposed to just parts of it.
Data stored in a NoSQL database such as HBase, Cassandra, or MongoDB. Data is placed in this type of storage for random access. Placing data in NoSQL can increase the processing speed if only some significant part of the data should be processed. For example, if a user needs to process only 10 percent of the data according to some criteria, they can reduce the data processing time by putting the data in NoSQL and building the index according to the chosen filter.
Data stored in RDBMS, as is common in many legacy applications. One of the ways Savanna can provide a way to process this data is to enable integration with Apache Sqoop. Sqoop was designed for transferring bulk data between Hadoop and structured data stores, such as relational databases. So after starting cluster services and before submitting a job, you would populate the cluster using Sqoop.
By Alexander Kuznetsov Read more
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...