ETL VS ELT: The Key Differences

In this article, we will explore the topic of ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) to avoid confusion between these two data integration methods. Both of them have advantages as well as downsides. Which type to choose depends on your needs in data analytics, speed of delivery, and a few more points.
The increasing complexity of business needs demands enormous amounts of information be available at one click. In practical terms, we store necessary ready-to-use data in data warehouses. But before, it has to be collected from a heterogeneous landscape of source systems and integrated into an intelligible form that the requester can withdraw.
Traditionally, this was done using an Extract-Transform-Load (ETL) method. However, advancing economic and technical changes since the establishment of this technology inevitably affected the data integration design. These include, among other points, the sharp fall in prices for virtual archives space, reduced electronic processing times, the establishment of cloud and online storage, and the overall development of a SaaS model of software developed in the cloud for the cloud. It led to the transformation of the data transfer mechanism into the Extract-Load-Transform (ELT) series.
However, it would be wrong to say that any data integration options have become outdated. Each still has several advantages next to the other. And we will try to figure out the reasons for such equal and sometimes simultaneous runs in a moment.
The essence of ETL and ELT models
First, it is necessary to analyze the essence of the ETL process, which, with all its pros and cons, is still utilized for the predominantly on-premise data structures. Its first step, ‘Extract,’ corresponds to extracting raw data from various sources. These can be, for example, websites, different types of documents and files, business applications, etc.
Find the entire web about this method of data suitable for working here.
Their subsequent ‘Transformation’ takes place within the operational server. The non-conforming data is brought into a preprocessed form to comply with the warehouse demands. This concerns the elimination of duplicates, conversion of units, normalization, grouping, and checking the plausibility of data.
During the closing ‘Loading,’ the refined data is transferred to the target database and available to the end-user.
As you might have guessed, the main interest in ETL processes is getting tailored data right off the reel. This also saves working capacities during the transformation, and no incorrect, redundant, or unnecessary data goes through the staging phase. Consequently, having time-tested practices and working tools since the first DBMS, ETL adherents focus on small masses of relational data for their needs.
Meanwhile, this makes the ETL process inflexible and difficult to expand due to the strong dependencies on extraction and transformation. The complete ETL process requires a lot of computing power in a separate staging database and therefore takes place in practice mostly during the lowest load capacity at night.
The time costs increase more with the addition of new data, which must be manually selected, while the old information may lose its value even at the processing stage. Add to this the cost of purchasing special hardware, and you get significant restrictions on the scope of its implementation.
In this way, the apparent benefit of ETL lies in an easy-to-handle and accurate data load with low chances of errors. In contrast, its downside is low scalability, speed, and flexibility.
There is a new ETL to handle the emerging disadvantages of the traditional ETL process. The transformation phase takes place only after loading data into the data warehouse. This modification of the original ETL process solves the existing problems by saving storage space and creating the possibility of using the target database’s computing power instead.
The most significant advantage of ELT it’s speed and flexibility, while the downside is its high price.
Key differences between ETL and ELT
This section will highlight three critical areas in which significant differences between ETL and ELT are apparent.
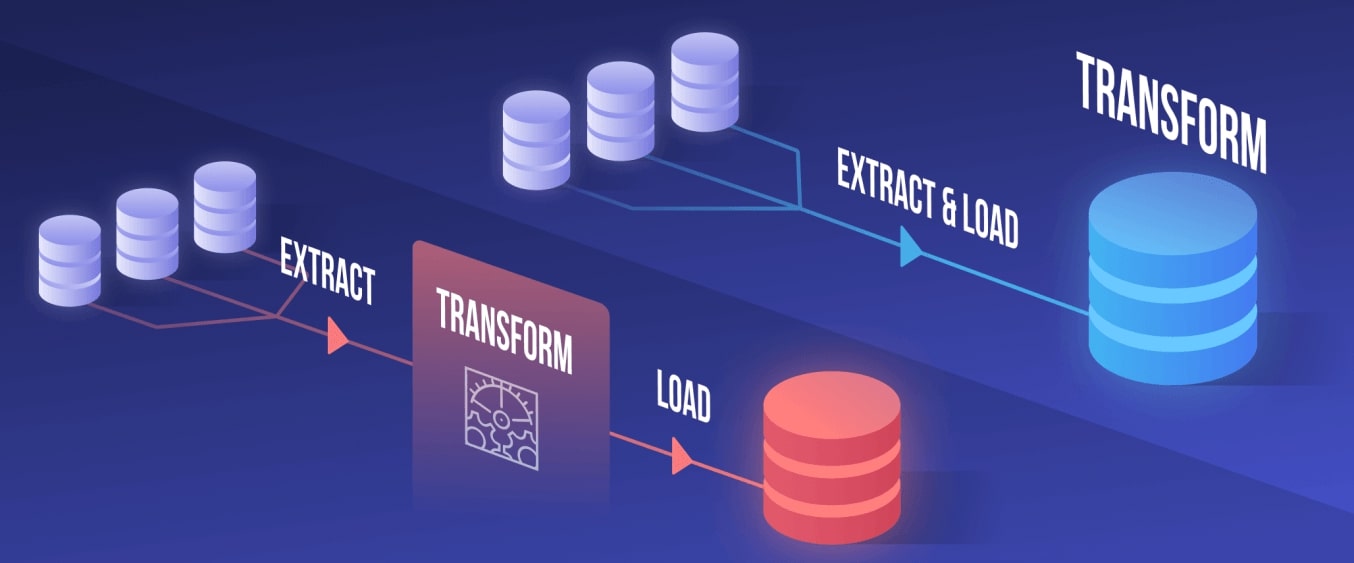
Source: Snowflake Solutions
A load of data
In the ELT approach, data is loaded right before the transformation. With ELT, the conversion only takes place in the target database. The main contrast is where the processing takes place. In the ETL model, data processing takes place in the database engine.
When it comes to the speed and amount of data, ELT is a winner here. This approach allows faster loading and processing of data compared to ETL.
Maintenance and data availability
A significant advantage of ELT technology is lower maintenance and constant data availability. Thus, the ELT process can be scaled as required by computing expansions of the data warehouse and does not depend on the power of the staging area. In the output, you reduce the time for analyzing information since the entire archive will be immediately available for reading after its withdrawal.
In contrast to ETL, redundant or useless data may also be available in the cloud. It can be removed or made meaningful manually during the transformation. However, this may not be necessary when working with large masses of data, given the low-price availability of modern online storage platforms.
The ETL model requires more operations and manual procedures with data. Data must be continuously extracted to be available with the least possible delay. This means that the number of operational processes carried out increases significantly, but the amount of data per extraction process decreases. Due to its time-consuming nature, the transformation can no longer be carried out with every warehouse update process.
Model scalability
We mentioned flexibility already, and we should also consider the opportunity to scale these approaches. As a cloud-based solution, ELT is much more friendly for scaling up. In opposite, ETL requires costly hardware, setups, and experts skills. It might not be complex to configure only in the early stages.
There are mixed forms of both options about scalability, for example, ETLT. Here, simple transformation steps occur before loading, while the computationally intensive transformation processes are carried out in the target database. Not to mention the reverse ETL process, which allows you to put data back in for front-line use in software.
Which method to use?
Because data in the ELT process is wholly transferred to the final destination without an upstream processing server, the time lag between extraction and provision is significantly shorter. However, we cannot use data immediately, given that the system analyses it first.
So if a high recording speed is required, ELT may be the better choice. In addition, the ability to access raw data adds a plus point, provided that data scientists deal with an immediate analysis. ELT is now often favored instead of ETL in the big data environment.
Which of the two systems to use depends greatly on your preferences and facilities. If you have a robust database engine and suitable hardware and can manipulate them heavily, then ELT will be a better choice.
However, database-oriented tools like Google BigQuery demand ‘Extract’ and ‘Load’ to be performed before the data is transformed and then compressed with SQL or PL/SQL code to consort with the target data warehouse. Alternatively, you can use one of BigQuery integrations to effortlessly transfer data from multiple platforms.
Therefore, despite the apparent advantages of the ELT model, the load preceding the transformation scheme also has its admirers. It depends on the individual case.
Wrap up
The ETL and ELT models stand close to each other, but they have noticeable differences.
ETL is a mature, established, and stable approach, compliant with all the data processing regulations. Though it might be cost-consuming and requires a lot of manual manipulations
ELT is a newer, faster, and more flexible solution that perfectly fits small and medium businesses’ needs.
The critical thing in the model selection lies in your personal data management and analytics needs.

About Author: Olena Prykhodko is a Marketing Specialist at Coupler.io, a data integration tool. She has 1+ years of experience in outreach and content marketing. Olena loves networking with people, so connect to her on Linkedin and share your feedback about the article.
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...