10 Hadoop Hardware Leaders
 Hadoop software is designed to orchestrate massively parallel processing on relatively low-cost servers that pack plenty of storage close to the processing power. All the power, reliability, redundancy, and fault tolerance is built into the software, which distributes the data and processing across tens, hundreds, or even thousands of “nodes” in a clustered server configuration.
Hadoop software is designed to orchestrate massively parallel processing on relatively low-cost servers that pack plenty of storage close to the processing power. All the power, reliability, redundancy, and fault tolerance is built into the software, which distributes the data and processing across tens, hundreds, or even thousands of “nodes” in a clustered server configuration.
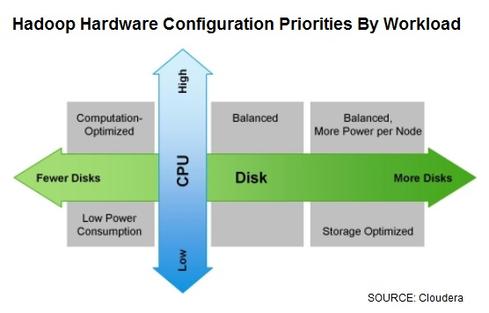
Those nodes are “industry standard” x86 servers that cost $2,500 to $5,000 each — depending on CPU, RAM, and disk choices. They’re usually middle-of-the-road servers in terms of performance specs. A standard DataNode (a.k.a. Worker node) server, for example, is typically a 2U rack server with a two-socket Intel Sandy Bridge or Ivy Bridge CPU with a total of 12 processors. Each CPU is typically fitted with 64 GB to 128 GB of RAM, and there are usually a dozen 2 or 3 TB 3.5-inch hard drives in a JBOD (just a bunch of disks) configuration.
Companies seeking a bit more performance, for Spark in-memory analysis or Cloudera Impala, for example, might choose slightly higher clock speeds, 256 GB or more RAM per CPU, while those seeking maximum capacity are choosing 4 TB hard drives.
Management nodes running Hadoop’s NameNode (which coordinates data storage) and JobTracker (which coordinates data processing) require less storage but benefit from more reliable power supplies, enterprise-grade disks, RAID redundancy, and a bit more RAM. Connecting the nodes together is a job for redundant 10-Gigabit Ethernet or InfiniBand switches.
It’s not uncommon for huge Fortune 100 companies to buy so-called whitebox servers from no-name OEMs for less than $2,000 a crack in high volumes, but it’s more typical for the average enterprise to work with Tier 1 vendors such as Cisco, Dell, HP, and IBM. All of these manufacturers now offer servers specifically configured for Hadoop reference architectures for Cloudera, Hortonworks, MapR, and other Hadoop distributions.
1. Cisco offers Unified Computing System.
Cisco’s Unified Computing System (UCS) is anchored by the C240 M3 server (the 2U rackmount server pictured above). Up to 16 of these servers fit in racks together with redundant Cisco UCS 6200 Series Fabric Interconnects. A single rack offers 168 terabytes of storage in a performance configuration, 384 terabytes in a balanced configuration, or 768 terabytes in a capacity-optimized configuration. Up to 10 racks can be connected in a single UCS domain for a total of 7.68 petabytes of storage. The configuration pictured is for MapR, but Cisco also offers reference architectures for Cloudera and Hortonworks Hadoop distributions.
2. Dell delivers a disk-intensive server.
Dell’s ringer for big data Hadoop deployments is the disk-heavy R720XD sever (pictured above with five in a rack). The R720XD packs up to 26 2.5-inch drives or 12 3.5-inch drives plus two 2.5-inch drives. Dell offers a reference architecture for Cloudera deployments, and it’s also a supplier of hardware for Microsoft HD Insight and Microsoft Analytics Platform System (APS) appliances. Both of these appliances run the Hortonworks-developed HD Insight software for Hadoop on Windows. APS includes Microsoft SQL Server 2014 as well as HD Insight.
3. HP “racks” up big data in a box.
HP’s favorites for Hadoop deployments are the DL360p sever for management and head nodes and disk-intensive DL380e servers for data nodes. They’re all pictured above in a full rack along with redundant HP 10-Gigabit Ethernet switches. Management and head nodes use four to eight super-reliable 900 gigabyte SAS drives. Data nodes get 12 capacious multi-terabyte SATA drives and two smaller SATA drives for system overhead. The Cloudera configuration pictured here also includes the community edition of HP’s Vertica massively parallel processing (MPP) database, which can be deployed on the same cluster. HP also has configurations for Hortonworks and MapR, and it supplies hardware for Microsoft HD Insight and Microsoft Analytics Platform System (APS) appliances.
4. IBM and Lenovo partner on x86.
x86 servers are the name of the game where Hadoop is concerned, but IBM views it as a commodity market. As announced in January, IBM plans to sell its xSeries business to Lenovo in a $2.3 billion deal that’s expected to close by year’s end (pending regulatory approval).
The close of the sale will make the IBM x3650 M4 BD part of the Lenovo lineup. “BD” is for big data, and the x3650 lives up to the name with space for 14 3.5-inch drives that can hold up to 56 terabytes. Lenovo will become an OEM supplier of x86 servers to IBM, which will continue to use these servers in selected IBM PureApplication and IBM PureData Systems appliances. One such product is the IBM PureData System for Hadoop, which features IBM’s InfoSphere BigInsights Hadoop distribution. You can read and hear all the details on short- and long-range support plans for x86 products here. IBM Power8 chips due out in June will reportedly support Hadoop deployment, and we’ll be watching closely to see if the appeal extends beyond IBM’s own BigInsights Hadoop distribution.
5. Supermicro courts big data crowd.
Supermicro might not have a Tier 1 name, but it’s super-aggressive in the big data arena, offering 14U and 42U preconfigured cluster racks. Anchoring these deployments are Hadoop FatTwin 4U hot-swappable servers and numerous other configuration options for NameNodes and DataNodes. Supermicro has recommended configurations for Apache Hadoop, Cloudera, and Hortonworks distributions.
6. Oracle Big Data Appliance blends NoSQL, Hadoop.
Oracle’s engineered system for Hadoop is the Oracle Big Data Appliance, which premiered in 2012 and was upgraded last year with the latest Intel drives and big 4 TB disk drives for a total capacity of 864 terabytes for a full rack. The BD Appliance is based largely on the same hardware used for Oracle Exadata. The 2013 upgrade brought a 1/3-rack purchase option, so you can start with a modest cluster and build it out and add racks as needed.
7. Pivotal mixes database and Hadoop options.
EMC was early to the Hadoop appliance game in 2011, long before it spun off its Greenplum database and Hadoop distribution as part of Pivotal. The Pivotal Data Computing Appliance replaces the Greenplum DCA, supporting modular deployments of the Pivotal HD Hadoop distribution, the Greenplum MPP database, or both within a single clustered platform. EMC adds plentiful storage options, including Isilon scale-out network-attached storage devices.
8. Teradata offers three deployment options for Hadoop.
Teradata has embraced Hadoop as part of its Unified Data Architecture, and it’s supporting it with three hardware deployment options. All options start with the Hortonworks Data Platform, which Teradata sells and supports as a software reseller. The first option is the Teradata Commodity Offering for Hadoop for customers who prefer to run on industry-standard hardware. In this case, the hardware is from Dell.
9. Cray supercomputing platform meets Hadoop.
Cray CS300 cluster supercomputers have been adapted to handle what the vendor calls “high value” Hadoop deployments. It’s an option whereby Cray customers can work with a single vendor to address all needs. You can choose direct-attached disk storage or the Cray Sonexion scale-out Lustre storage system. Cray CS300 systems are liquid- or air-cooled, and there are plenty of disk, processor, and switch options. Customers can blend Hadoop and clustered supercomputing workloads in a single environment, using the Cray-optimized Simple Linux Utility for Resource Management.
10. SGI delivers maximum computing power.
The SGI InfiniteData Cluster is a scale-out computing platform typically geared to high-performance computing, but it also runs Apache Hadoop and Cloudera software. The InfiniteData Cluster’s 1:1 core-to-spindle ratio delivers a 48% analytics performance boost over more typical 3:1 ratio clusters, according to SGI. The cluster combines high density, performance, and scale, with a single rack packing in 1,920 cores and 1.9 petabytes of storage capacity — roughly two times the compute and disk space of more typical enterprise-class clusters. Source
Related Posts

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...