An introduction to Apache Hadoop for big data
 Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware. Hadoop is an Apache top-level project being built and used by a global community of contributors and users. It is licensed under the Apache License 2.0.
Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware. Hadoop is an Apache top-level project being built and used by a global community of contributors and users. It is licensed under the Apache License 2.0.
Hadoop was created by Doug Cutting and Mike Cafarella in 2005. It was originally developed to support distribution for the Nutch search engine project. Doug, who was working at Yahoo! at the time and is now Chief Architect of Cloudera, named the project after his son’s toy elephant. Cutting’s son was 2 years old at the time and just beginning to talk. He called his beloved stuffed yellow elephant “Hadoop” (with the stress on the first syllable). Now 12, Doug’s son often exclaims, “Why don’t you say my name, and why don’t I get royalties? I deserve to be famous for this!”
The Apache Hadoop framework is composed of the following modules
- Hadoop Common: contains libraries and utilities needed by other Hadoop modules
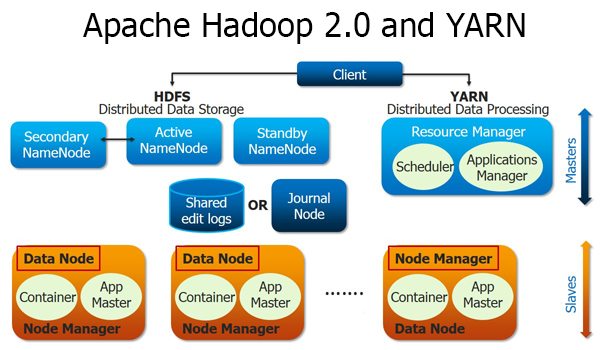
- Hadoop Distributed File System (HDFS): a distributed file-system that stores data on the commodity machines, providing very high aggregate bandwidth across the cluster
- Hadoop YARN: a resource-management platform responsible for managing compute resources in clusters and using them for scheduling of users’ applications
- Hadoop MapReduce: a programming model for large scale data processing
All the modules in Hadoop are designed with a fundamental assumption that hardware failures (of individual machines, or racks of machines) are common and thus should be automatically handled in software by the framework. Apache Hadoop’s MapReduce and HDFS components originally derived respectively from Google’s MapReduce and Google File System (GFS) papers.
Beyond HDFS, YARN and MapReduce, the entire Apache Hadoop “platform” is now commonly considered to consist of a number of related projects as well: Apache Pig, Apache Hive, Apache HBase, and others.
For the end-users, though MapReduce Java code is common, any programming language can be used with “Hadoop Streaming” to implement the “map” and “reduce” parts of the user’s program. Apache Pig and Apache Hive, among other related projects, expose higher level user interfaces like Pig latin and a SQL variant respectively. The Hadoop framework itself is mostly written in the Java programming language, with some native code in C and command line utilities written as shell-scripts.
HDFS and MapReduce
There are two primary components at the core of Apache Hadoop 1.x: the Hadoop Distributed File System (HDFS) and the MapReduce parallel processing framework. These are both open source projects, inspired by technologies created inside Google. Read more
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...