How Does Data Lake Architecture Work?
Since its conception in October 2010 by James Dixon, data lake has undergone a myriad of developments and is now used globally by a lot of firms. To understand how a data lake works or what it can be used for, we must first understand what it means.
A data lake is a storage space where large amounts of data can be stored in their raw formats, the type of data to be stored may be structured, semi-structured, or unstructured data. Data lakes may be used for data exploration, data analytics, and machine learning.
Now that we know what a data lake is, we can go over what the data lake architecture is, and how it works.
Fundamentals of Data Lake Architecture
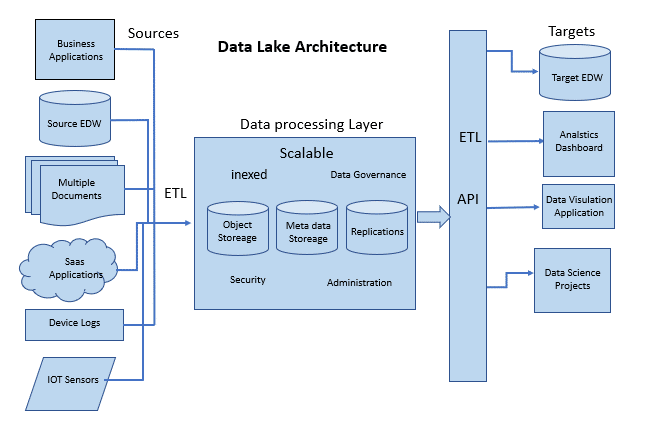
The data lake architecture is designed to ensure the return of the best possible result from the data storage unit. That said, there are several components in the architecture that make data lake functional.
Data ingestion and Data Storage
Data lake absorbs information from several sources such as databases, applications e.t.c, a data lake can also ingest data from a data warehouse.
The main difference between a data lake and a data warehouse is that, unlike a data warehouse, a data lake does not need to convert or refine data before it can store it. The ingested data is stored in a limitless central storage unit where it is converted into open data formats, after which it is optimized for consumption.
Data Processing
After the conversion of the data into open data formats, it is prepared for consumption via various engineering routes called engineering pipelines. Depending on their scale footprints, the open data might need large scalable pipelines to be ready for data consumption. As an added advantage, large scalable pipelines have complex data organizing functions. Data processing engines such as Apache Spark and Apache Hive can be employed for desired performance and results.
Data Governance
In an organization, multiple personnel gain access to data. When this happens, it becomes necessary to control the security and pay attention to the consumption of data by unauthorized personnel.
One surefire way to tighten the security is to encrypt the information in the data lake. The data is stored in the cloud, therefore, the cloud providers distribute encryption keys to their clients. These keys give access to the data stored in the cloud, and only people with access to the encryption keys can access data stored in the data lake.
Data Discovery and Analysis
Before preparing the processed data for analysis and consumption, the information in the data lake needs to be expressed and translated. Data tagging techniques are used in this case, to organize and translate the data.
A domain-specific programming language, SQL, is normally utilized for the analysis of the data in a data lake, especially for business purposes. In addition, Open Database Connectivity (ODBC) and Java Database Connectivity (JDBC) drivers can be used to run third-party SQL clients.
Related Posts

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...

7 Top Autonomous AI Pentesting Platforms in 2026
June 10, 2026Autonomous penetration testing is becoming one of the most important changes in ...

How the Right Infrastructure Unlocks Better AML Engine Performance
May 30, 2026Many anti-money laundering (AML) engines underperform or generate excessive false positives because ...

Why Embedded Analytics Is Replacing Standalone BI for Customer-Facing Use Cases
May 16, 2026The business intelligence market is undergoing an architectural split. For internal reporting ...

Why Agentic AI Requires More Than Better Models
April 30, 2026Agentic artificial intelligence (AI) is set to fundamentally reshape the structure of ...