HBase BlockCache Showdown
 The HBase BlockCache is an important structure for enabling low latency reads. As of HBase 0.96.0, there are no less than three different BlockCache implementations to choose from. But how to know when to use one over the other? There’s a little bit of guidance floating around out there, but nothing concrete. It’s high time the HBase community changed that! I did some benchmarking of these implementations, and these results I’d like to share with you here.
The HBase BlockCache is an important structure for enabling low latency reads. As of HBase 0.96.0, there are no less than three different BlockCache implementations to choose from. But how to know when to use one over the other? There’s a little bit of guidance floating around out there, but nothing concrete. It’s high time the HBase community changed that! I did some benchmarking of these implementations, and these results I’d like to share with you here.
Note that this is my second post on the BlockCache. In my previous post, I provide an overview of the BlockCache in general as well as brief details about each of the implementations. I’ll assume you’ve read that one already.
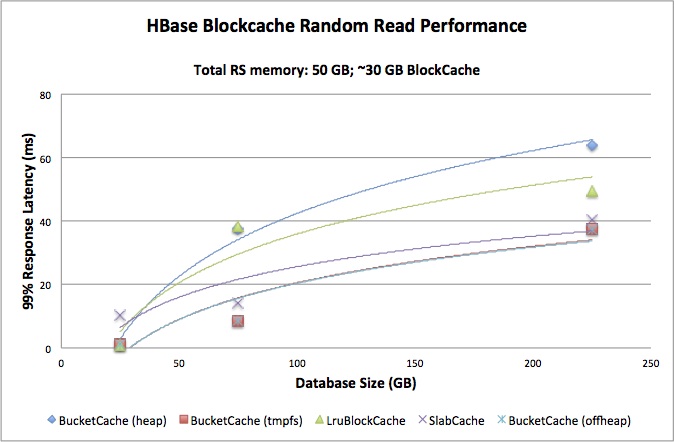
The goal of this exercise is to directly compare the performance of different BlockCache implementations. The metric of concern is that of client-perceived response latency. Specifically, the concern is for the response latency at the 99th percentile of queries – that is, the worst case experience that the vast majority of users will ever experience. With this in mind, two different variables are adjusted for each test: RAM allotted and database size.
The first variable is the amount of RAM made available to the RegionServer process and is expressed in gigabytes. The BlockCache is sized as a portion of the total RAM allotted to the RegionServer process. For these tests, this is fixed at 60% of total RAM. The second variable is the size of the database over which the BlockCache is operating. This variable is also expressed in gigabytes, but in order to directly compare results generated as the first variable changes, this is also expressed as the ratio of database size to RAM allotted. Thus, this ratio is a rough description for the amount “cache churn” the RegionServer will experience, regardless of the magnitude of the values. With a smaller ratio, the BlockCache spends less time juggling blocks and more time servicing reads.
Test Configurations
The tests were run across two single machine deployments. Both machines are identical, with 64G total RAM and 2x Xeon E5-2630@2.30GHz, for a total of 24 logical cores each. The machines both had 6x1T disks sharing HDFS burden, spinning at 7200 RPM. Hadoop and HBase were deployed using Apache Ambari from HDP-2.0. Each of these clusters-of-one were configured to be fully “distributed,” meaning that all Hadoop components were deployed as separate processes. The test client was also run on the machine under test, so as to omit any networking overhead from the results. The RegionServer JVM, Hotspot 64-bit Server v1.6.0_31, was configured to use the CMS collector.
Configurations are built assuming a random-read workload, so MemStore capacity is sacrificed in favor of additional space for the BlockCache. The default LruBlockCache is considered the baseline, so that cache is configured first and its memory allocations are used as guidelines for the other configurations. The goal is for each configuration to allow roughly the same amount of memory for the BlockCache, the MemStores, and other activities of the HBase process itself. Read more
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...