Can Super-Fast Apache Spark Light Up Hadoop?
 it the Hadoop Swiss Army knife of cluster computing frameworks. The Apache Software Foundation just rolled out Apache Spark v1.0, which it’s calling a “super-fast, open-source, large-scale Relevant Products/Services data Relevant Products/Services processing and advanced analytics Relevant Products/Services engine.”
it the Hadoop Swiss Army knife of cluster computing frameworks. The Apache Software Foundation just rolled out Apache Spark v1.0, which it’s calling a “super-fast, open-source, large-scale Relevant Products/Services data Relevant Products/Services processing and advanced analytics Relevant Products/Services engine.”
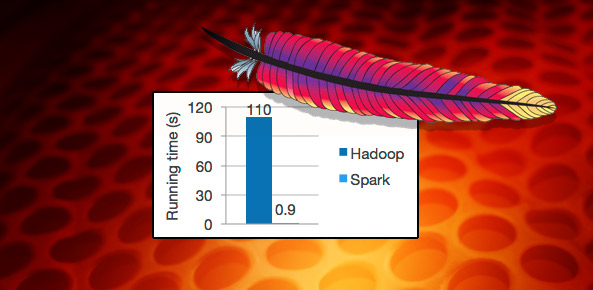
That’s a mouthful, indeed, but why has the technology been dubbed a Hadoop Swiss Army knife? Because Spark lets developers write apps in Java, Scala or Python with a built-in set of more than 80 high-level operators. Apache claims Spark makes possible programs that can run up to 100 times faster than Apache Hadoop MapReduce in memory.
“Apache Spark is an important big data technology in delivering a high-performance analytics solution for the IT industry and satisfying the fast-growing customer Relevant Products/Services demand,” said Michael Greene, vice president and general manager of System Technologies and Optimization at Intel Relevant Products/Services.
Who Does this Target?
Apache Spark aims at groups that need to tap into machine learning, interactive queries, and stream processing. Spark is fully compatible with Hadoop’s Distributed File System, HBase, Cassandra, and any Hadoop storage Relevant Products/Services system, so existing data is immediately available in Spark. Spark also promises support for SQL queries, streaming data and complex analytics, including machine learning and graph algorithms, right out of the box.
Patrick Wendell, software Relevant Products/Services engineer at Databricks and Apache Spark 1.0 release manager, explained that the new release not only provides long-term stability for Spark’s core APIs, it also offers several new features.
“Spark 1.0 adds a unified submission tool for deploying applications on a local machine, Mesos, YARN, or a dedicated cluster,” said Wendell. “We’ve added a new module, Spark SQL, to provide schema-aware data modeling and SQL language support in Spark. Spark’s machine learning library, MLLib, has been enhanced with several new algorithms. Spark’s streaming and graph libraries have also seen major updates. Across the board, we’ve focused on building tools to empower the data scientists, statisticians and engineers who must grapple with large data sets every day.”
NASA Is All-In
Originally developed at UC Berkeley AMP Lab, Spark is in use by companies like Alibaba, ClearStory Data, Cloudera, Databricks, IBM, Intel, MapR, Ooyala and Yahoo. Beyond enterprise Relevant Products/Services adoption, Apache Spark is also winning code contributors to the project.
Chris Mattmann, who is an Apache Software Foundation (ASF) director and chief architect in the Instrument and Science Data Systems Section at the National Aeronautics and Space Administration Jet Propulsion Laboratory, said NASA is excited to leverage Spark and its “highly interactive analytic capabilities.” He also pointed to the speedups 1.0 offers, and said Spark SQL as helpful to critical projects looking at measurement of snow in the western U.S., as well as on projects related to regional climate modeling and in model evaluation for the National Climate Assessment.
“I’m looking forward to designing Spark-related projects in my software architectures and in my search engines courses at USC as well,” said Mattmann, who also is an adjunct associate professor there. “The community is one of our most active at the ASF, and the interest has really peaked and these guys are doing a great job.” Source
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...