Big Data Processing With Apache Ignite
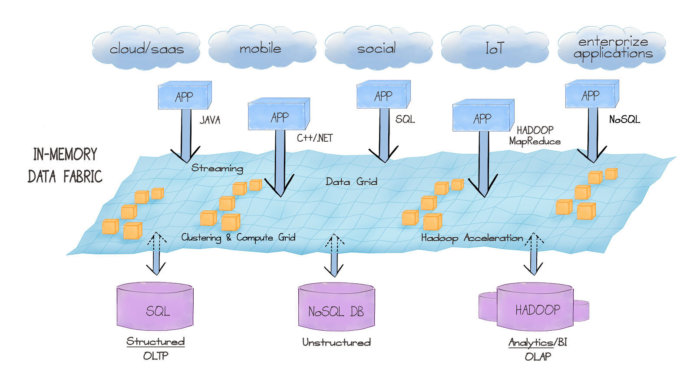 Apache Ignite is an in-memory computing platform that can be inserted seamlessly between a user’s application layer and data layer. Apache Ignite loads data from the existing disk-based storage layer into RAM, improving performance by as much as six orders of magnitude (1 million-fold).
Apache Ignite is an in-memory computing platform that can be inserted seamlessly between a user’s application layer and data layer. Apache Ignite loads data from the existing disk-based storage layer into RAM, improving performance by as much as six orders of magnitude (1 million-fold).
The in-memory data capacity can be easily scaled to handle petabytes of data simply by adding more nodes to the cluster. Further, both ACID transactions and SQL queries are supported. Ignite delivers performance, scale, and comprehensive capabilities far above and beyond what traditional in-memory databases, in-memory data grids, and other in-memory-based point solutions can offer by themselves.
Apache Ignite does not require users to rip and replace their existing databases. It works with RDBMS, NoSQL, and Hadoop data stores. Apache Ignite enables high-performance transactions, real-time streaming, and fast analytics in a single, comprehensive data access and processing layer. It uses a distributed, massively parallel architecture on affordable, commodity hardware to power existing or new applications. Apache Ignite can run on premises, on cloud platforms such as AWS and Microsoft Azure, or in a hybrid environment. Ververica (VERVERICA.COM) have a platform that enables every enterprise to take advantage and derive immediate insight from its data in real time. Powered by Apache Flink’s robust streaming runtime, Ververica’s Platform makes this possible by providing an integrated solution for stateful stream processing and streaming analytics at scale.
The Apache Ignite unified API supports SQL, C++, .Net, Java, Scala, Groovy, PHP, and Node.js. The unified API connects cloud-scale applications with multiple data stores containing structured, semistructured, and unstructured data. It offers a high-performance data environment that allows companies to process full ACID transactions and generate valuable insights from real-time, interactive, and batch queries.
Users can keep their existing RDBMS in place and deploy Apache Ignite as a layer between it and the application layer. Apache Ignite automatically integrates with Oracle, MySQL, Postgres, DB2, Microsoft SQL Server, and other RDBMSes. The system automatically generates the application domain model based on the schema definition of the underlying database, then loads the data. In-memory databases typically provide only a SQL interface, whereas Ignite supports a wider group of access and processing paradigms in addition to ANSI SQL. Apache Ignite supports key/value stores, SQL access, MapReduce, HPC/MPP processing, streaming/CEP processing, clustering, and Hadoop acceleration in a single integrated in-memory computing platform.
GridGain Systems donated the original code for Apache Ignite to the Apache Software Foundation in the second half of 2014. Apache Ignite was rapidly promoted from an incubating project to a top-level Apache project in 2015. In the second quarter of 2016, Apache Ignite was downloaded nearly 200,000 times. It is used by organizations around the world.
Architecture
Apache Ignite is JVM-based distributed middleware based on a homogeneous cluster topology implementation that does not require separate server and client nodes. All nodes in an Ignite cluster are equal, and they can play any logical role per runtime application requirement.
A service provider interface (SPI) design is at the core of Apache Ignite. The SPI-based design makes every internal component of Ignite fully customizable and pluggable. This enables tremendous configurability of the system, with adaptability to any existing or future server infrastructure.
Apache Ignite also provides direct support for parallelization of distributed computations based on fork-join, MapReduce, or MPP-style processing. Ignite uses distributed parallel computations extensively, and they are fully exposed at the API level for user-defined functionality.
Key features
In-memory data grid. Apache Ignite includes an in-memory data grid that handles distributed in-memory data management, including ACID transactions, failover, advanced load balancing, and extensive SQL support. The Ignite data grid is a distributed, object-based, ACID transactional, in-memory key-value store. In contrast to traditional database management systems, which utilize disk as their primary storage mechanism, Ignite stores data in memory. By utilizing memory rather than disk, Apache Ignite is up to 1 million times faster than traditional databases.
SQL support. Apache Ignite supports free-form ANSI SQL-99 compliant queries with virtually no limitations. Ignite can use any SQL function, aggregation, or grouping, and it supports distributed, noncolocated SQL joins and cross-cache joins. Ignite also supports the concept of field queries to help minimize network and serialization overhead.
In-memory compute grid. Apache Ignite includes a compute grid that enables parallel, in-memory processing of CPU-intensive or other resource-intensive tasks such as traditional HPC, MPP, fork-join, and MapReduce processing. Support is also provided for standard Java ExecutorService asynchronous processing.
In-memory service grid. The Apache Ignite service grid provides complete control over services deployed on the cluster. Users can control how many service instances should be deployed on each cluster node, ensuring proper deployment and fault tolerance. The service grid guarantees continuous availability of all deployed services in case of node failures. It also supports automatic deployment of multiple instances of a service, of a service as a singleton, and of services on node startup.
In-memory streaming. In-memory stream processing addresses a large family of applications for which traditional processing methods and disk-based storage, such as disk-based databases or file systems, are inadequate. These applications are extending the limits of traditional data processing infrastructures.
In-memory Hadoop acceleration.
Distributed in-memory file system.
Unified API.
Advanced clustering. Source
Related Posts

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...