Splunk’s Hunk 6.1enables faster analytics for Hadoop and NoSQL Data Stores
 Splunk Inc. announced version 6.1 of Hunk: Splunk Analytics for Hadoop and NoSQL Data Stores. Hunk 6.1 makes it even faster and easier to turn raw, unstructured data in Hadoop and NoSQL data stores into business insights. Accelerated reports in Hunk significantly improve reporting times, while interactive dashboards deliver rich self-service analytics without fixed schemas or the need to move data.
Splunk Inc. announced version 6.1 of Hunk: Splunk Analytics for Hadoop and NoSQL Data Stores. Hunk 6.1 makes it even faster and easier to turn raw, unstructured data in Hadoop and NoSQL data stores into business insights. Accelerated reports in Hunk significantly improve reporting times, while interactive dashboards deliver rich self-service analytics without fixed schemas or the need to move data.
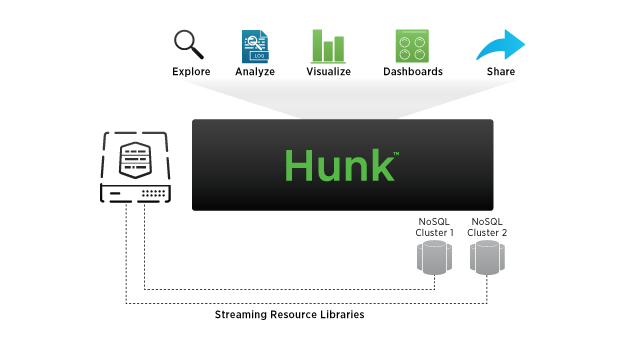
Hunk 6.1 extends the power of Hunk beyond Hadoop through streaming resource libraries for NoSQL and other data stores such as Apache Accumulo, Apache Cassandra, MongoDB and Neo4j.
Hunk 6.1 contains significant new and updated product features to help organizations unlock the business value of data in Hadoop and NoSQL data stores. Splunk Virtual Index, a patent-pending technology that decouples the storage tier from the data access and analytics tiers enabling Hunk to route requests to different data stores. It also includes report acceleration which transparently cache search results in Hadoop, improving reporting response times and performance without moving data, and drives efficient utilization of Hadoop resources – as the amount of data grows and the number of queries increases.
Hunk 6.1 also builds interactive dashboards and charts with a new dashboard editor to deliver enhanced analytics experience with charting overlay, pan-and-zoom controls and in-dashboard drill downs, and embeds Hunk charts and dashboards into common third-party business applications. It also streams Resource Libraries which enables developers to stream data from NoSQL and other data stores, such as Apache Accumulo, Apache Cassandra, MongoDB and Neo4j, for exploration, analysis and visualization in Hunk.
Hunk 6.1 offers support for multiple file formats which automates access to text files, sequence files, Record Columnar Files (RCFile), Optimized Row Columnar (ORC) files and Parquet columnar files. It also features pass-through authentication which enables submission of MapReduce jobs and secure access to Hadoop clusters using the authenticated credentials and roles assigned by IT.
Hunk includes a dominant environment for developers to build big data applications using the languages and frameworks they already use and are familiar with. Hunk includes a standards-based web framework, documented REST API, Eclipse plug-in and software development kits for C#, Java, JavaScript, Python, PHP and Ruby. Read more
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...