Hadoop Can’t Do These Things, Surprised To Know What They Are?
The world of Big Data is alluring. With the craze of digitalization and technology boom, Large volumes of data started blocking up the servers. Circumstantially, Hadoop came to the feat and initiated the processing of big data speedily. As Hadoop is changing the understanding of handling big data, specifically unstructured data. Many organizations are using Hadoop in their IT infrastructure.
What is Hadoop?
It is an open-source java-based software framework used for processing and storing big data in a distributed computing environment on large clusters of commodity hardware nodes. With its Distributed File System, it is possible to handle thousands of terabyte data and also provides a faster data transfer among the nodes and allows the system to seamlessly continue its operations in case of node failure. Hadoop is also called as Apache Hadoop, as is a part of Apache project, which is sponsored by Apache Software Foundation.
Hadoop Distributed File System (HDFS):
Hadoop DFS is set out to run on commodity hardware. This system stores large amounts of data ranging from gigabytes to terabytes crossover different machines. It provides data awareness between jobtracker and tasktracker. Job tracker reduce jobs or schedule maps to task tracker with awareness in data location simplifying the data management process. The two main components of Hadoop are HDFS and Data Processing framework.
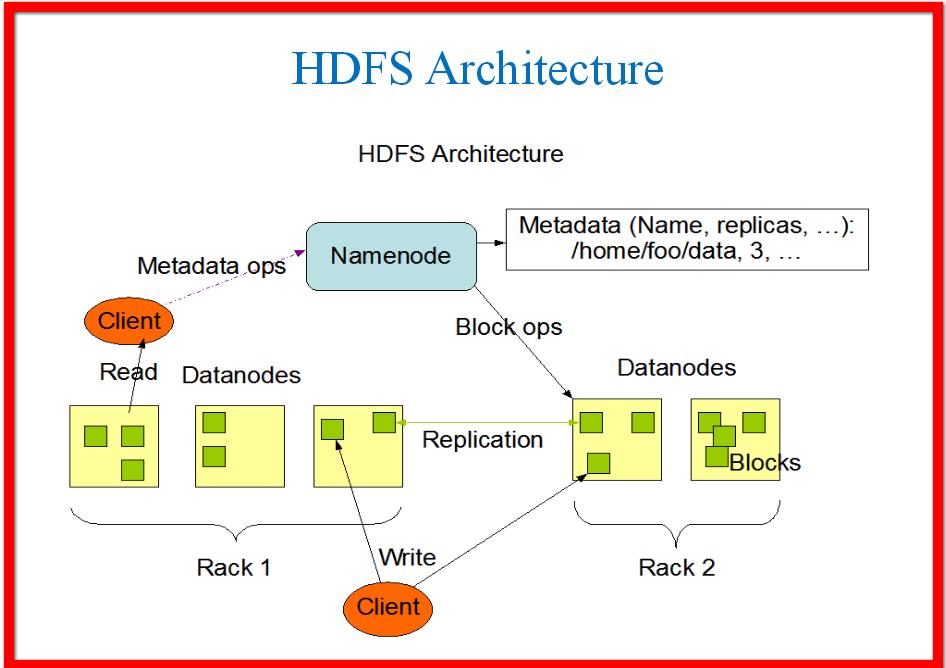
- HDFS: This is used to handle data effectively over different machines in the system and implements a model that is multiple-reader and single-writer supporting operations to write, read and delete files and also in creating and deleting directories.
- Data Processing Framework: This tool is a java-based system called as Mapreduce, and is used for processing the data.
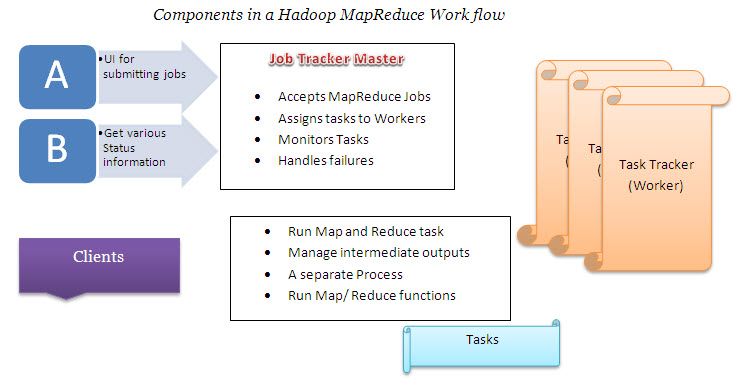
Jobtracker handles data coming from Mapreduce and assigns tasks to workers, monitors the tasks, manages the entire process and also takes care of failures if occurred. The jobtracker lifts work out to accessible tasktracker nodes in the cluster trying to keep the work as close as possible to the data. Jobtracker knows what way all the steps has to be followed in the architecture and hence reduces the traffic that evolves from the network by unifying the racks and their respective nodes.
Previously, businesses were not able to analyze small amounts of data and kept on hold for the solution. But now the scenario is different, daily loads of data is jamming the servers and Hadoop came out as a solution for analyzing big data. But Hadoop users say that there are certain things that Hadoop cannot do and here are some of those.
- Low Latency SQL Access with ACID Compliance: There are plenty of ways to access hadoop data with SQL. Hadoop users are increasingly growing with increase in their business data. A fact is that not all hadoop users drop ACID (Atomicity, Consistency, Isolation, and Durability) and only SQL access was identified as considerably a great way to fill up the Big data analytics skills gap. In Spite of this, it is observed by hadoop users that SQL access on hadoop is highly expensive as you need lot of specialized skills and time to work it out. Business people find it going for bigger oracle or ibm netezza appliance as a better option.
- CRUD Operations: Hadoop cannot update, insert or delete operations but it can append. Actian vortex uses a technique that not only does update, full insert and delete operations but also does with concurrency without letting down the query speed.
- Batch Processing Without Writing Code: If a business user is interested in using hadoop then he must hire troops of mapreduce coders to build and maintain workflows on hadoop. It was a decade ago that hadoop was batch only, base level Mapreduce and HDFS starting point. Many think that hadoop and mapreduce are synonymous, but not is the case.
The post is by Priyanka Maheshwaram, a Content Writer at TekSlate and possess immense interest in internet security, video games, science and technology.
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...