Google BigQuery and Datastore Connectors for Hadoop
Users of Google’s cloud platform should find it easier to run Hadoop jobs directly against data in Google BigQuery and Google Cloud Datastore from now on.
we are making it easier for you to run Hadoop jobs directly against your data in Google BigQuery and Google Cloud Datastore with the Preview release of Google BigQuery connector and Google Cloud Datastore connector for Hadoop. The Google BigQuery and Google Cloud Datastore connectors implement Hadoop’s InputFormat and OutputFormat interfaces for accessing data. These two connectors complement the existing Google Cloud Storage connector for Hadoop, which implements the Hadoop Distributed File System interface for accessing data in Google Cloud Storage.
The connectors can be automatically installed and configured when deploying your Hadoop cluster using bdutil simply by including the extra “env” files:
- ./bdutil deploy bigquery_env.sh
- ./bdutil deploy datastore_env.sh
- ./bdutil deploy bigquery_env.sh datastore_env.sh
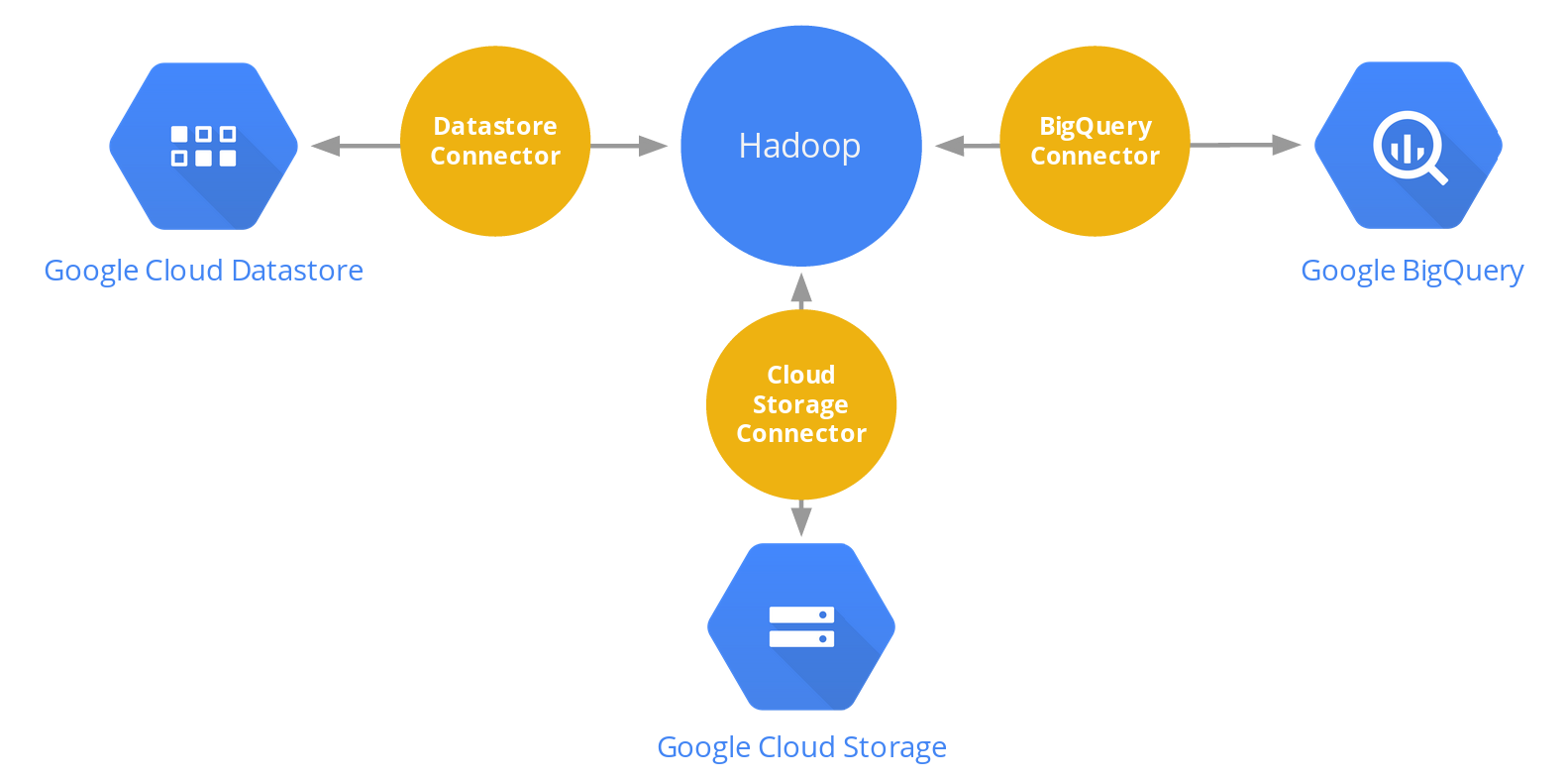 These three connectors allow you to directly access data stored in Google Cloud Platform’s storage services from Hadoop and other Big Data open source software that use Hadoop’s IO abstractions. As a result, your valuable data is available simultaneously to multiple Big Data clusters and other services, without duplications. This should dramatically simplify the operational model for your Big Data processing on Google Cloud Platform.
These three connectors allow you to directly access data stored in Google Cloud Platform’s storage services from Hadoop and other Big Data open source software that use Hadoop’s IO abstractions. As a result, your valuable data is available simultaneously to multiple Big Data clusters and other services, without duplications. This should dramatically simplify the operational model for your Big Data processing on Google Cloud Platform.
Here are some word-count MapReduce code samples to get you started:
- Using the BigQuery connector
- Using the Datastore connector
- Using the Datastore connector for reading data and using the BigQuery connector for publishing results
As always, we would love to hear your feedback and ideas on improving these connectors and making Hadoop run better on Google Cloud Platform. Source
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

Primary Considerations for Building Resilience in Your Disaster Recovery Plan
June 15, 2026Without a solid disaster plan, system failures can plunge operations into the ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...