Apache Falcon-Data Governance for Hadoop
 Apache Falcon is a data governance engine that defines, schedules, and monitors data management policies. Falcon allows Hadoop administrators to centrally define their data pipelines, and then Falcon uses those definitions to auto-generate workflows in Apache Oozie.
Apache Falcon is a data governance engine that defines, schedules, and monitors data management policies. Falcon allows Hadoop administrators to centrally define their data pipelines, and then Falcon uses those definitions to auto-generate workflows in Apache Oozie.
InMobi is one of the largest Hadoop users in the world, and their team began the project 2 years ago. At the time, InMobi was processing billions of ad-server events in Hadoop every day. The InMobi team started the project to meet their need for policies to manage how that data flowed into and through their cluster—specifically for replication, lifecycle management, and data lineage and traceability.
This became the Apache Falcon incubator project in April 2013. Since it became an Apache incubator project, three Falcon releases have resolved nearly 400 JIRAs with contributions from many individuals in the open source community.
Apache Falcon will ship with Hortonworks Data Platform version 2.1. This is the first time that Falcon will be included in a top-tier Hadoop distribution.
Although Falcon is a newer addition to the Hadoop ecosystem, it has already been running in production at InMobi for nearly two years. InMobi uses it for various processing pipelines and data management functions, including SLA feedback pipelines and revenue pipelines.
What does Apache Falcon do?
Apache Falcon simplifies complicated data management workflows into generalized entity definitions. Falcon makes it far easier to:
- Define data pipelines
- Monitor data pipelines in coordination with Ambari, and
- Trace pipelines for dependencies, tagging, audits and lineage.
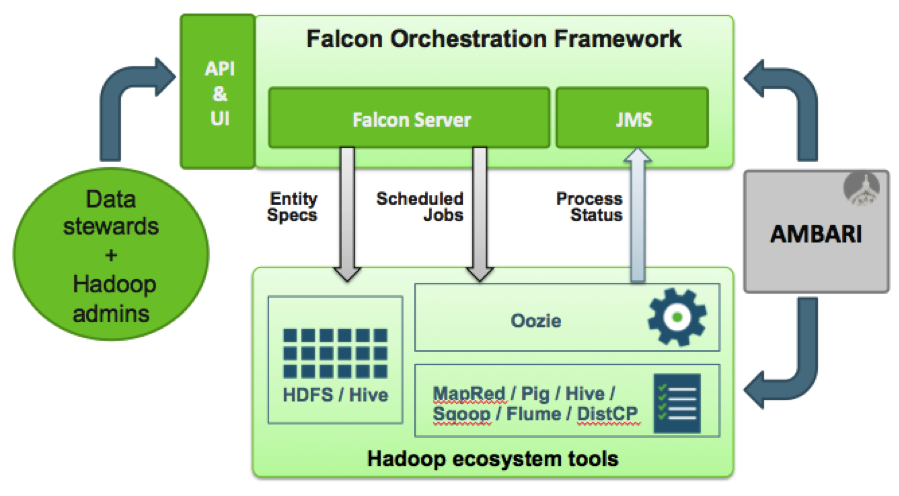
This architecture diagram, gives a high-level view of how Falcon interacts with the Hadoop cluster to define, monitor and trace pipelines:
Apache Oozie is Hadoop’s workflow scheduler, but mature Hadoop clusters can have hundreds to thousands of Oozie coordinator jobs. At that level of complexity, it becomes difficult to manage so many data set and process definitions. read more
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...