Using Hunk with Hadoop and Elastic MapReduce
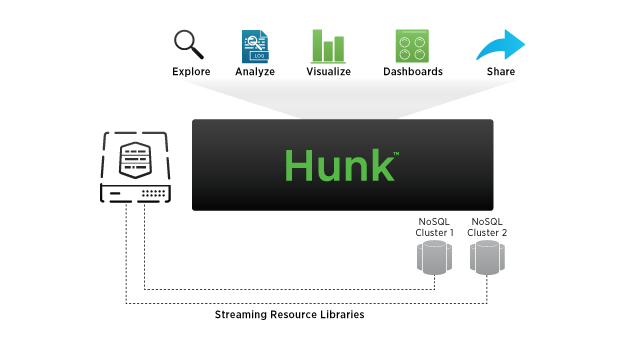 Hunk is a relatively new product from Splunk for exploring and visualizing Hadoop and other NoSQL data stores. New in this release is support for Amazon’s Elastic MapReduce.
Hunk is a relatively new product from Splunk for exploring and visualizing Hadoop and other NoSQL data stores. New in this release is support for Amazon’s Elastic MapReduce.
Hunk with Hadoop
Hadoop consists of two components, the first being a storage component called HDFS. HDFS can be distributed across tens thousands of replicated nodes. The second component MapReduce, which tracks and manages the map-reduce jobs it is named for.
In the past, developers would use Splunk Hadoop Connect (SHC). SHC supports exporting data to Hadoop using a normal push model, which works reasonably well. Going the other direction is where problems can arise. When exploring data using Splunk, the raw data is sucked into Splunk servers for indexing and processing. As one would imagine, this doesn’t properly take advantage of Hadoop’s compute capabilities.
Hunk solves this by providing an adapter that works with Hadoop MapReduce nodes. Splunk queries are converted into Hadoop MapReduce jobs, processed in the Hadoop cluster, and then only the results are brought back into Splunk for analysis and visualization.
In this manner, Hunk provides an abstraction layer so that users and developers don’t need to know how to directly write Hadoop MapReduce jobs. It can also provide result previews before the MapReduce job is even started, reducing the number of wasted searches.
Hunk with Elastic MapReduce
Amazon Elastic MapReduce can be seen as both a compliment and a competitor to Hadoop. EMR can run on top of a Hadoop HDFS cluster, but it can also run directly on top of AWS S3. The claimed advantage of using AWS S3 is that it is easier to manage than a HDFS cluster.
Hunk offers the same abstraction and preview capabilities when running against Elastic MapReduce as it does with Hadoop. So from the user’s perspective, nothing change when switching between Hadoop and EMR.
Hunk on the Cloud
The traditional method for hosting Hunk in the cloud is to simply buy a standard license and then provision a virtual machine much in the same way you would do it on-site. The instance would then have to be manually configured to point to the correct Hadoop or AWS cluster.
New for this month’s release, Hunk instances can be automatically provisioned in AWS. This includes automatically discovering the EMR data sources, which allows for instances to be brought online in a manner of minutes. In order to take advantage of this, Hunk instances are billed at an hourly rate.
Virtual Indexes
A key concept in Hunk is “Virtual Indexes”. These are not indexes in sense of the word, but rather are just the way Hadoop and EMR clusters are exposed by Hunk. From the Splunk UI they look just like real indexes, even though the data is processed using map-reduce jobs. And since it looks like an index, you can create persistent secondary indexes on top of them. This is useful when you want to partially process the data, then further examine or visualize the data in multiple ways. source
Related Posts

Universal Design Principles for Accessible E-commerce Websites
April 25, 2024In the digital age, e-commerce websites are more than just business platforms; ...

Taking Your Online Game Global: Essential Tips for Successful Launches
April 25, 2024The online gaming industry is a global powerhouse. A Statista report shows ...

How to Utilize an AI Math Tool for Quick Solutions
April 25, 2024Mathematics can often feel like an insurmountable challenge, with its complex equations ...

How Energy Efficiency Analysis Benefits Businesses
April 24, 2024In today's business landscape, energy efficiency is not just a buzzword—it's a ...

10 Types of Businesses That Need Shopify Web Development
April 24, 2024Shopify has emerged as a leading platform for e-commerce success, renowned for ...