3 Techniques To Speed Up Data Annotation
Computer vision can easily distinguish between well-defined shapes, for instance, a sphere and a cube. Things go awry with less distinct forms. It’s easy for the human eye to differentiate between a cat and a dog — you know what is what. But computers have no such innate capability, and even the most advanced computer vision algorithms often mistake a cat for a dog and vice versa.
Computers have to be trained rigorously to classify fuzzy objects. That training is imparted with special hardware and algorithms which constitute the platform termed ‘Deep Learning,’ a subset of Artificial Intelligence (AI). Conceptually, deep learning uses Artificial Neural Networks (ANNs) to simulate how the human brain learns, thinks and adapts.
Over the last decade, deep learning has seen explosive growth in computer vision. The platform has made many advances in a range of computer vision problems: object detection, motion tracking, action recognition, human pose estimation, and semantic segmentation.
A key component in training deep learning systems for computer vision is data annotation. Data annotation denotes labeling objects of interest in training media. This enables computer vision algorithms to recognize objects and interpret their surroundings correctly. The quality of the training data you use hinges on the quality of your annotations. Annotations thus underpin computer vision projects and their success or failure.
Data Annotation Types
There are various data annotation modalities, depending on the data form. In the world of computer vision, common types of data that are annotated are:
- Text — Nearly 70% of companies rely on text. Not surprisingly, a commonly used data type for annotation is text. A typical text annotation task is text categorization, which assigns categories to sentences or paragraphs in a document. Further text annotation tasks include sentiment annotation, intent annotation, and semantic annotation.
- Audio — Audio annotation is the transcription and time-stamping of speech data. This includes a transcription of the speaker’s pronunciation and intonation and identification of language, dialect, and speaker demographics.
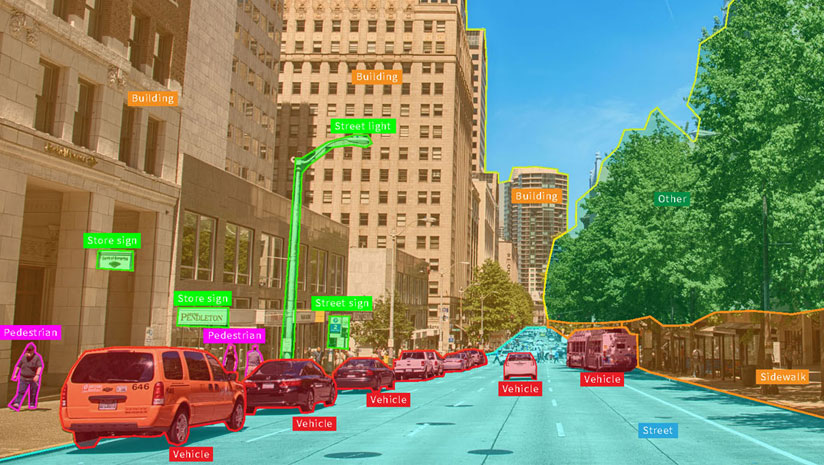
- Image — Image annotation lets machines recognize an annotated area as a distinct object and often involves drawing bounding boxes around objects of interest and semantic segmentation (assigning meaning to every pixel). Image annotation is key to a wide range of applications, including computer vision, robotic vision, facial recognition, and solutions that rely on deep learning to interpret images.
- Video — Video annotation works similar to image annotation, using bounding boxes but on a frame-by-frame basis or via a video annotation tool to perceive motion. Video annotation undergirds computer vision models that perform object tracking.
Annotation Tools
Annotations are rendered with dedicated software tools, many of which are Open Source. Widely used annotation tools include Labellmg, Computer Vision Annotation Tool (CVAT), Visual Object Tagging Tool (VOTT), VGG Image Annotator (VIA), and LabelMe.
When choosing the right annotation tool for your computer vision project, there are a few factors to consider.
- Efficiency — Annotations are manual by nature, so labeling can eat up time and other resources. If a tool provides a convenient user interface and hotkey support, it can save time and improve annotation quality.
- Functionality — A label can serve one out of a choice of annotation functions, primarily: classification, object detection, semantic segmentation. So it would be best if you used a tool that supports all the functions you need in your annotations.
- Supported annotation shapes — Commonly used shapes and patterns in image annotations are 2D Bounding Boxes, 3D Bounding Boxes/Cuboids, Landmarks (sequence of points), and Polygons. Annotation tools do not always support all shapes. Labellmg, for instance, is limited to 2D Bounding Boxes.
- Output formats — If you have a target output format in mind, you want your annotation tool to be capable of producing an output in the format you need: COCO JSON / CSV / TFRecord / Pascal VOC XML.
- Web-based vs. local application — Some annotation tools are web-based, while others can run as local applications. Again, you have to choose what methodology suits you best.
- Price — Obviously, you want to keep the price down as much as possible while snapping up all the features you need.
You know a tool is right for you when it works well for your project on all counts mentioned above.
Optimizing Data Annotation
Despite the use of annotation tools, data annotation remains largely a manual process demanding patient and accurate work. Much of the efficacy of the dataset used to train a computer vision model depends on how well the data annotations educate the model in perceiving objects of interest.
Poor annotations could result in a man being identified as a woman or your algorithm interpreting the text “Buck Up!” as a salary increment. In short, annotations decide whether your model is ready for production or not.
Below are some commonly used annotation techniques.
- Manual Data Annotation — When datasets are small, or the goal is to build a prototype quickly, you can annotate a dataset manually. In this case, developers review the data and put labels on the data samples adhering to the annotation guidelines.
- Pros: needs minimal administration of data annotation efforts; better annotation quality.
- Cons: not scalable to large datasets; expensive and slow.
- Crowdsourcing Data Annotation — Crowdsourcing is a scalable and cost-effective data annotation method. There are several crowdsourcing platforms, such as Amazon Mechanical Turk and Crowdflower.
- Pros: cheap; scalable to large datasets; fast.
- Cons: Lower quality, which necessitates quality-control mechanisms.
- Data-Driven Data Annotation — In many computer vision projects, you can define simple rules that can solve the problem for a subset of the data. Suppose that subset is high-quality data and adequately representative. In that case, you can collect sufficient data sample-label pairs to train a deep learning model with a high generalization ability to deal with the entire dataset.
- Pros: free; requires minimal administration; scalable to large datasets.
- Cons: highly accurate extraction patterns might not always exist; data samples covered by the patterns might not be representative enough.
Over the last decade, Python has emerged as the programming language of choice for deep learning. Python’s PyTorch module enables moving datasets from disk to cloud storage and progressively streaming labels as you train your deep learning model. If you are starting a computer vision project, you should consider scaling computer vision with PyTorch.
Choices and Hard Work
Computer vision annotations need you to make a few balanced choices to train your deep learning model well enough. You have to select the right annotation tool for your project and then choose a sound annotation technique that quickly delivers high-quality annotations. Even with the correct choices, you still have to put in the time and hard work to ensure that annotations attain the quality needed for your model to be adequately trained for production environments.
Related Posts

Building an AI-Ready Data Strategy: What Every Enterprise Should Get Right Before Scaling Artificial Intelligence
July 16, 2026Enterprise AI initiatives rarely stall because teams lack access to capable models. ...

What Social Media Analytics Actually Tell You – and What They Don’t
July 13, 2026If you work in data, you have probably watched a marketing team ...

Best 7 Revenue Intelligence Solutions for Technical Sales Teams
June 26, 2026Technical sales teams operate in a fundamentally different environment than most B2B ...

5 Best Social Intelligence Tools for 2026
June 15, 2026Social intelligence has become one of the most important capabilities for brands ...

The 2026 Data Observability Vendor Database: 20+ Platforms by Founding Year, Funding, Hosting, and Pricing
June 12, 2026The data observability market has evolved rapidly over the past five years. ...