The 3 most common ways data junkies are using Hadoop
 Just a few weeks ago, Apache Hadoop 2.0 was declared generally available–a huge milestone for the Hadoop market as it unlocks the vision of interacting with stored data in unprecedented ways. Hadoop remains the typical underpinning technology of “Big Data,” but how does it fit into the current landscape of databases and data warehouses that are already in use? And are there typical usage patterns that can be used to distill some of the inherent complexity for us all to speak a common language?
Just a few weeks ago, Apache Hadoop 2.0 was declared generally available–a huge milestone for the Hadoop market as it unlocks the vision of interacting with stored data in unprecedented ways. Hadoop remains the typical underpinning technology of “Big Data,” but how does it fit into the current landscape of databases and data warehouses that are already in use? And are there typical usage patterns that can be used to distill some of the inherent complexity for us all to speak a common language?
Common patterns of Hadoop use
Hadoop was originally conceived to solve the problem of storing huge quantities of data at a very low cost for companies like Yahoo, Google, Facebook and others. Now, it is increasingly being introduced into enterprise environments to handle new classes of data. Machine-generated data, sensor data, social data, web logs and other such types are growing exponentially, but also often (but not always) unstructured in nature. It is this type of data that is turning the conversation from “data analytics” to “big data analytics”: because so much insight can be gleaned for business advantage.
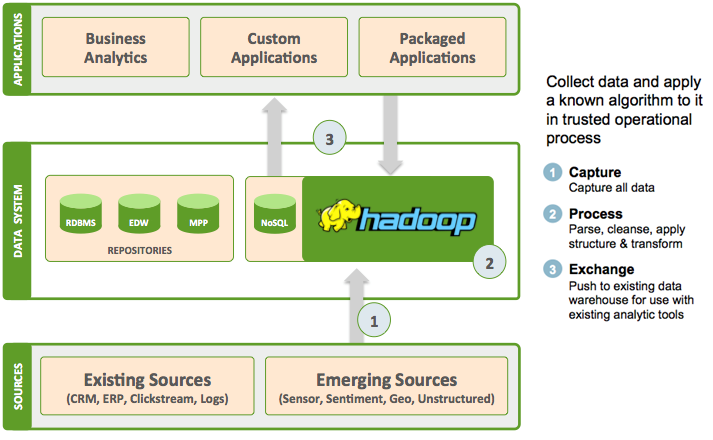
Analytic applications come in all shapes and sizes–and most importantly, are oriented around addressing a particular vertical need. At first glance, they can seem to have little relation to each other across industries and verticals. But in reality, when observed at the infrastructure level, some very clear patterns emerge: they can fit into one of the following three patterns.
Pattern 1: Data refinery
The “Data Refinery” pattern of Hadoop usage is about enabling organizations to incorporate these new data sources into their commonly used BI or analytic applications. For example, I might have an application that provides me a view of my customer based on all the data about them in my ERP and CRM systems, but how can I incorporate data from their web sessions on my website to see what they are interested in? The “Data Refinery” usage pattern is what customers typically look to.
The key concept here is that Hadoop is being used to distill large quantities of data into something more manageable. And then that resulting data is loaded into the existing data systems to be accessed by traditional tools–but with a much richer data set. In some respects, this is the simplest of all the use cases in that it provides a clear path to value for Hadoop with really very little disruption to the traditional approach. No matter the vertical, the refinery concept applies. In financial services, we see organizations refine trade data to better understand markets or to analyze and value complex portfolios. Energy companies use big data to analyze consumption over geography to better predict production levels. Retail firms (and virtually any consumer-facing organization) often use the refinery to gain insight into online sentiment. Telecoms are using the refinery to extract details from call data records to optimize billing. Finally, in any vertical where we find expensive, mission critical equipment, we often find Hadoop being used for predictive analytics and proactive failure identification. In communications, this may be a network of cell towers. A restaurant franchise may monitor refrigerator data.
Pattern 2: Data exploration with Apache Hadoop
The second most common use case is one we call “Data Exploration.” In this case, organizations capture and store a large quantity of this new data (sometimes referred to as a data lake) in Hadoop and then explore that data directly. So rather than using Hadoop as a staging area for processing and then putting the data into the enterprise data warehouse–as is the case with the Refinery use case–the data is left in Hadoop and then explored directly. Read more
Related Posts

7 Top Autonomous AI Pentesting Platforms in 2026
June 10, 2026Autonomous penetration testing is becoming one of the most important changes in ...

Why Embedded Analytics Is Replacing Standalone BI for Customer-Facing Use Cases
May 16, 2026The business intelligence market is undergoing an architectural split. For internal reporting ...

Designing Predictive Pipelines: How Enterprises Turn Data into Foresight
December 26, 2025Predictive analytics is now a structured part of how many enterprises operate. ...
How AI-Driven Mobility Data Is Transforming Urban Transportation in 2026
November 17, 2025Rent a car dubai services are increasingly relying on advanced data analytics ...

How Data Engineering Services Are Reshaping Global Business Strategies
October 24, 2025TL;DR Data engineering services have evolved into a critical pillar of enterprise strategy. ...