Sizing The Big Data Market-No One Has A Clue
 Forget all the Big Data numbers you’ve seen. The reality is that no one has a clue how much Big Data adoption there is, because few actually know what Big Data means.
Forget all the Big Data numbers you’ve seen. The reality is that no one has a clue how much Big Data adoption there is, because few actually know what Big Data means.
Ian Bertram, managing vice president at Gartner, points this out, arguing that the industry is completely muddled over what Big Data means. According to Gartner research, 50% of enterprises cite data variety, not data volume, as the primary driver of Big Data adoption. In fact, “big” is hardly a factor at all.
Marketo’s Jon Miller suggests that “big data is a catch-all term for data sets that are so large and complex that they necessitate new forms of processing beyond the SQL databases prevalent since the early 1980s.” Given that the term is merely a catch-all, how can we even be sure that a given application is a “Big Data application”?
This isn’t a Gartner problem. It’s an industry problem. We’ve invented a meaningless term that essentially means everything, and hence nothing.
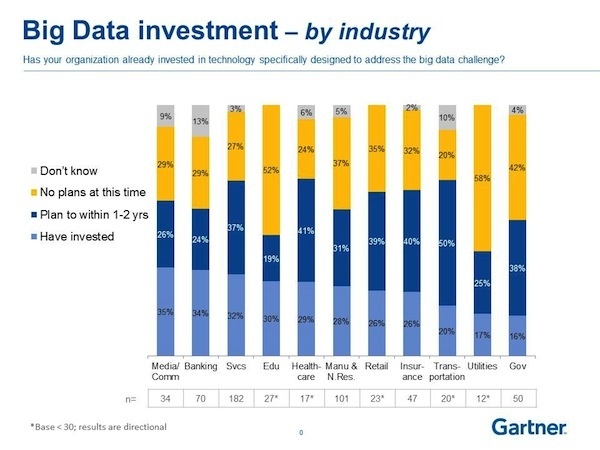
Hence, when Wikibon tries to quantify the Big Data businesses of a range of vendors, it’s hard to see how they (or anyone) can truly get anywhere near the right answer:
I suspect that what we’re really talking about with “Big Data” is merely data. We just mean that we’ve gained the ability to put more data to work in our applications. It’s not really a matter of “big,” though. It’s just a matter of “more.” Bertram seems to concur:
The question I would like pose is—why call it “Big Data” at all, what makes it big? Rather why not call it just “data” or “Information” as aren’t we just talking about different sources and extracting value from the combination of these sources? Aren’t we trying to find patterns to build models, identify risk, understand intent and sentiment and develop networks?
In other words, aren’t we just trying to do the same things that we’ve always tried to do, but with new tools like Hadoop and NoSQL that make it easier, more powerful and cost effective. The tools have changed, but the desire to put data to use has not. By Matt Asay Source
Related Posts

Top Innovations for Environment-Friendly Dumpster Rental Businesses
April 18, 2024In a world that’s gradually waking up to the environmental perils of ...

How to Leverage AI for Content Creation and Scheduling
April 17, 2024Content creation is the heartbeat of digital marketing and creative endeavors. It ...

How to Increase Magento Site Speed
April 17, 2024The speed of your Magento webstore is a crucial factor for both ...

How Emerging AI Technologies Enhance Intrusion Detection Systems
April 16, 2024Nowadays, robust security practices that involve a layered approach are the backbone ...

Unveiling SEO Treasures: Identify Keywords Beyond Your Competitors’ Reach
April 16, 2024Introduction Ever wondered how search engines like Google decide which websites to show ...