Impala and SQL on Hadoop
 The origins of Impala can be found in F1 – The Fault-Tolerant Distributed RDBMS Supporting Google’s Ad Business.
The origins of Impala can be found in F1 – The Fault-Tolerant Distributed RDBMS Supporting Google’s Ad Business.
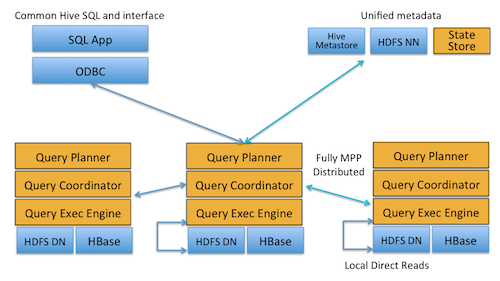
One of many differences between MapReduce and Impala is in Impala the intermediate data moves from process to process directly instead of storing it on HDFS for processes to get at the data needed for processing. This provides a HUGE performance advantage and doing so while consuming few cluster resources. Less hardware to-do more!
There are many advantages to this approach over alternative approaches for querying Hadoop data, including::
- Thanks to local processing on data nodes, network bottlenecks are avoided.
- A single, open, and unified metadata store can be utilized.
- Costly data format conversion is unnecessary and thus no overhead is incurred.
- All data is immediately query-able, with no delays for ETL.
- All hardware is utilized for Impala queries as well as for MapReduce.
- Only a single machine pool is needed to scale.
We encourage you to read the documentation for further exploration!
There are still transformation steps required to optimize the queries but Impala can help to-do this for you with Parquet file format. Better compression and optimized runtime performance is realized using the ParquetFormat though many other file types are supported. Read more
Related Posts

Top Innovations for Environment-Friendly Dumpster Rental Businesses
April 18, 2024In a world that’s gradually waking up to the environmental perils of ...

How to Leverage AI for Content Creation and Scheduling
April 17, 2024Content creation is the heartbeat of digital marketing and creative endeavors. It ...

How to Increase Magento Site Speed
April 17, 2024The speed of your Magento webstore is a crucial factor for both ...

How Emerging AI Technologies Enhance Intrusion Detection Systems
April 16, 2024Nowadays, robust security practices that involve a layered approach are the backbone ...

Unveiling SEO Treasures: Identify Keywords Beyond Your Competitors’ Reach
April 16, 2024Introduction Ever wondered how search engines like Google decide which websites to show ...